進入 3D:PDB 模組
Bio.PDB 是 Biopython 的一個模組,專注於處理生物巨分子的晶體結構。其中,Bio.PDB 包含一個 PDBParser 類別,它會產生一個 Structure 物件,可用於以方便的方式存取檔案中的原子數據。對解析 PDB 標頭中包含的資訊支援有限。PDB 檔案格式不再被修改或擴展以支援新內容,而 PDBx/mmCIF 在 2014 年成為標準的 PDB 檔案格式。所有全球蛋白質資料庫 (wwPDB) 站點都使用巨分子晶體學資訊檔 (mmCIF) 數據字典來描述 PDB 條目的資訊內容。mmCIF 使用靈活且可擴展的鍵值對格式來表示巨分子結構數據,並且對單個 PDB 條目中可以表示的原子、殘基或鏈的數量沒有限制 (沒有分割條目!)。
讀取與寫入晶體結構檔案
讀取 mmCIF 檔案
首先建立一個 MMCIFParser 物件
>>> from Bio.PDB.MMCIFParser import MMCIFParser
>>> parser = MMCIFParser()
然後使用這個解析器從 mmCIF 檔案建立一個結構物件
>>> structure = parser.get_structure("1fat", "1fat.cif")
要對 mmCIF 檔案進行更低層級的存取,可以使用 MMCIF2Dict 類別來建立一個 Python 字典,將 mmCIF 檔案中的所有 mmCIF 標籤對應到它們的值。無論是有多個值 (如標籤 _atom_site.Cartn_y 的情況,它保存所有原子的 \(y\) 坐標) 還是單個值 (如初始沉積日期),該標籤都對應到一個值列表。該字典是從 mmCIF 檔案建立的,如下所示
>>> from Bio.PDB.MMCIF2Dict import MMCIF2Dict
>>> mmcif_dict = MMCIF2Dict("1FAT.cif")
範例:從 mmCIF 檔案取得溶劑含量
>>> sc = mmcif_dict["_exptl_crystal.density_percent_sol"]
範例:取得所有原子的 \(y\) 坐標列表
>>> y_list = mmcif_dict["_atom_site.Cartn_y"]
讀取 BinaryCIF 檔案
建立一個 BinaryCIFParser 物件
>>> from Bio.PDB.binary_cif import BinaryCIFParser
>>> parser = BinaryCIFParser()
使用 BinaryCIF 檔案的路徑呼叫 get_structure
>>> parser.get_structure("1GBT", "1gbt.bcif.gz")
<Structure id=1GBT>
讀取 MMTF 格式的檔案
您可以使用直接的 MMTFParser 從檔案讀取結構
>>> from Bio.PDB.mmtf import MMTFParser
>>> structure = MMTFParser.get_structure("PDB/4CUP.mmtf")
或者您可以使用相同的類別,通過其 PDB ID 取得結構
>>> structure = MMTFParser.get_structure_from_url("4CUP")
這會給您一個結構物件,如同從 PDB 或 mmCIF 檔案讀取的一樣。
您也可以使用 Biopython 內部使用的外部 MMTF 函式庫存取基礎數據
>>> from mmtf import fetch
>>> decoded_data = fetch("4CUP")
例如,您可以只存取 X 坐標。
>>> print(decoded_data.x_coord_list)
讀取 PDB 檔案
首先,我們建立一個 PDBParser 物件
>>> from Bio.PDB.PDBParser import PDBParser
>>> parser = PDBParser(PERMISSIVE=1)
PERMISSIVE 標誌表示,將忽略與 PDB 檔案相關的一些常見問題 (請參閱範例) (但請注意,會遺失某些原子和/或殘基)。如果沒有這個標誌,如果在解析操作期間偵測到任何問題,則會產生 PDBConstructionException。
然後,讓 PDBParser 物件解析 PDB 檔案,來產生 Structure 物件 (在本例中,PDB 檔案稱為 pdb1fat.ent,1fat 是使用者定義的結構名稱)
>>> structure_id = "1fat"
>>> filename = "pdb1fat.ent"
>>> structure = parser.get_structure(structure_id, filename)
您可以使用 get_header 和 get_trailer 方法從 PDBParser 物件中提取 PDB 檔案的標頭和尾部 (簡單的字串列表)。但是,請注意,許多 PDB 檔案包含具有不完整或錯誤資訊的標頭。許多錯誤已在等效的 mmCIF 檔案中修正。因此,如果您對標頭資訊感興趣,最好使用上面描述的 ``MMCIF2Dict`` 工具從 mmCIF 檔案中提取資訊,而不是解析 PDB 標頭。
現在已經澄清了,讓我們回到解析 PDB 標頭。結構物件有一個名為 header 的屬性,它是一個 Python 字典,將標頭記錄對應到它們的值。
範例
>>> resolution = structure.header["resolution"]
>>> keywords = structure.header["keywords"]
可用的鍵有 name、head、deposition_date、release_date、structure_method、resolution、structure_reference (對應到參考文獻列表)、journal_reference、author、compound (對應到一個字典,其中包含有關結晶化合物的各種資訊)、has_missing_residues、missing_residues 和 astral (對應到一個字典,其中包含有關網域的其他資訊,如果存在)。
has_missing_residues 對應到一個布林值,如果發現至少一個非空的 REMARK 465 標頭行,則為 True。在這種情況下,您應該假設實驗中使用的分子有一些殘基無法確定 ATOM 坐標。missing_residues 對應到一個字典列表,其中包含有關遺失殘基的資訊。如果 PDB 標頭不遵循 PDB 規範中的範本,則遺失殘基列表將為空或不完整。
字典也可以在不建立 Structure 物件的情況下建立,例如直接從 PDB 檔案建立。
>>> from Bio.PDB import parse_pdb_header
>>> with open(filename, "r") as handle:
... header_dict = parse_pdb_header(handle)
...
讀取 PQR 檔案
為了剖析 PQR 檔案,請以與 PDB 檔案類似的方式進行。
建立一個 PDBParser 物件,使用 is_pqr 旗標。
>>> from Bio.PDB.PDBParser import PDBParser
>>> pqr_parser = PDBParser(PERMISSIVE=1, is_pqr=True)
將 is_pqr 旗標設定為 True 表示要剖析的檔案是 PQR 檔案,並且剖析器應讀取每個原子條目的原子電荷和半徑欄位。 依照與 PQR 檔案相同的程序,接著會產生一個 Structure 物件,並剖析 PQR 檔案。
>>> structure_id = "1fat"
>>> filename = "pdb1fat.ent"
>>> structure = parser.get_structure(structure_id, filename, is_pqr=True)
讀取 PDBML (PDB XML) 檔案
建立一個 PDBMLParser 物件。
>>> from Bio.PDB.PDBMLParser import PDBMLParser
>>> pdbml_parser = PDBMLParser()
使用包含 XML 格式 PDB 結構的檔案路徑或檔案物件來呼叫 get_structure。
>>> structure = pdbml_parser.get_structure("1GBT.xml")
寫入 mmCIF 檔案
MMCIFIO 類別可用於將結構寫入 mmCIF 檔案格式。
>>> io = MMCIFIO()
>>> io.set_structure(s)
>>> io.save("out.cif")
Select 類別的使用方式與下方的 PDBIO 類似。 使用 MMCIF2Dict 讀取的 mmCIF 字典也可以寫入。
>>> io = MMCIFIO()
>>> io.set_dict(d)
>>> io.save("out.cif")
寫入 PDB 檔案
使用 PDBIO 類別來執行此操作。當然,也很容易寫出結構的特定部分。
範例:儲存結構
>>> io = PDBIO()
>>> io.set_structure(s)
>>> io.save("out.pdb")
如果您想要寫出結構的一部分,請使用 Select 類別(也在 PDBIO 中)。Select 有四個方法:
accept_model(model)accept_chain(chain)accept_residue(residue)accept_atom(atom)
預設情況下,每個方法都會傳回 1(表示模型/鏈/殘基/原子包含在輸出中)。透過子類化 Select 並在適當時傳回 0,您可以從輸出中排除模型、鏈等。可能很麻煩,但功能非常強大。下列程式碼只會寫出甘胺酸殘基:
>>> class GlySelect(Select):
... def accept_residue(self, residue):
... if residue.get_name() == "GLY":
... return True
... else:
... return False
...
>>> io = PDBIO()
>>> io.set_structure(s)
>>> io.save("gly_only.pdb", GlySelect())
如果這對您來說太複雜了,Dice 模組包含一個方便的 extract 函式,可寫出鏈中開始和結束殘基之間的所有殘基。
寫入 PQR 檔案
使用 PDBIO 類別,就像處理 PDB 檔案一樣,並使用旗標 is_pqr=True。PDBIO 方法也可用於 PQR 檔案。
範例:寫入 PQR 檔案
>>> io = PDBIO(is_pqr=True)
>>> io.set_structure(s)
>>> io.save("out.pdb")
寫入 MMTF 檔案
將結構寫入 MMTF 檔案格式:
>>> from Bio.PDB.mmtf import MMTFIO
>>> io = MMTFIO()
>>> io.set_structure(s)
>>> io.save("out.mmtf")
上述可以使用 Select 類別。請注意,標準 MMTF 檔案中包含的鍵結資訊、二級結構指派和一些其他資訊不會寫出,因為從結構物件中不容易判斷。此外,在標準 MMTF 檔案中分組到相同實體中的分子會被 MMTFIO 視為個別實體。
結構表示法
Structure 物件的整體佈局遵循所謂的 SMCRA(結構/模型/鏈/殘基/原子)架構:
一個結構由多個模型組成。
一個模型由多條鏈組成。
一條鏈由多個殘基組成。
一個殘基由多個原子組成。
這是許多結構生物學家/生物資訊學家思考結構的方式,並提供一種簡單但有效的方法來處理結構。基本上,其他內容會在需要時新增。 Structure 物件的 UML 圖(暫時忘記 Disordered 類別)顯示在圖 3 中。這種資料結構不一定最適合表示結構的大分子內容,但對於正確解釋描述結構的檔案(通常是 PDB 或 MMCIF 檔案)中的資料絕對必要。如果此階層無法表示結構檔案的內容,則可以肯定該檔案包含錯誤,或者至少沒有明確地描述結構。如果無法產生 SMCRA 資料結構,則有理由懷疑存在問題。因此,剖析 PDB 檔案可用於偵測可能的問題。我們將在範例部分中給出幾個範例。
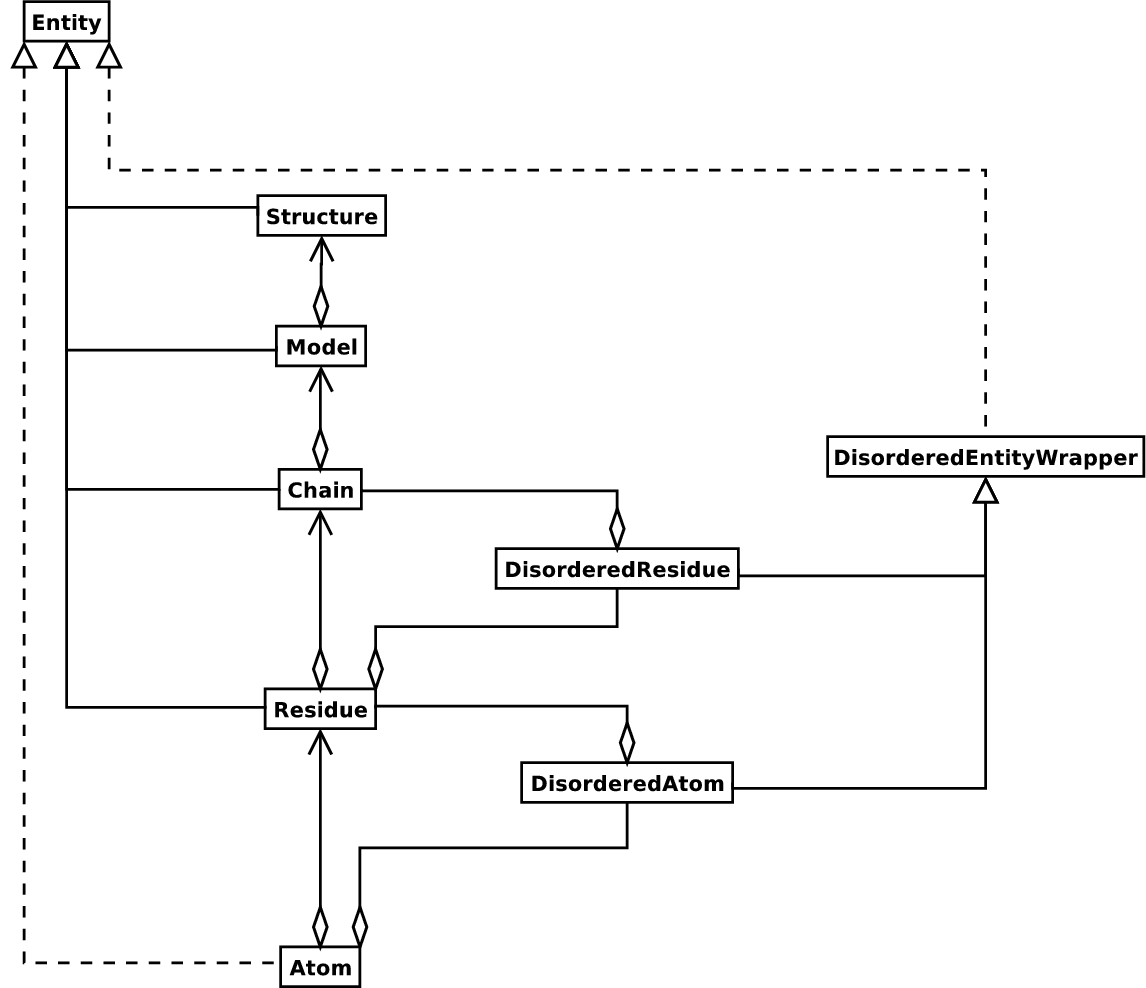
圖 3 Structure 類別的 SMCRA 架構 UML 圖。
這用於表示巨分子結構。帶有菱形的全線表示聚合,帶有箭頭的全線表示參考,帶有三角形的全線表示繼承,帶有三角形的虛線表示介面實現。
Structure、Model、Chain 和 Residue 都是 Entity 基底類別的子類別。Atom 類別僅(部分)實作 Entity 介面(因為 Atom 沒有子系)。
對於每個 Entity 子類別,您可以使用該子系的唯一 ID 作為索引鍵來提取子系(例如,您可以使用原子名稱字串作為索引鍵,從 Residue 物件提取 Atom 物件;您可以使用其鏈識別碼作為索引鍵,從 Model 物件提取 Chain 物件)。
無序的原子和殘基由 DisorderedAtom 和 DisorderedResidue 類別表示,它們都是 DisorderedEntityWrapper 基底類別的子類別。它們隱藏了與無序相關的複雜性,並且行為與 Atom 和 Residue 物件完全相同。
一般而言,可以使用 ID 作為索引鍵從其父系(分別是 Residue、Chain、Model、Structure)提取子系 Entity 物件(即 Atom、Residue、Chain、Model)。
>>> child_entity = parent_entity[child_id]
您也可以取得父系 Entity 物件的所有子系 Entity 的清單。請注意,此清單會以特定方式排序(例如,根據 Model 物件中 Chain 物件的鏈識別碼)。
>>> child_list = parent_entity.get_list()
您也可以從子系取得父系。
>>> parent_entity = child_entity.get_parent()
在 SMCRA 階層的所有層級中,您也可以提取*完整 ID*。完整 ID 是一個元組,其中包含從頂層物件(Structure)到目前物件的所有 ID。例如,Residue 物件的完整 ID 如下:
>>> full_id = residue.get_full_id()
>>> print(full_id)
("1abc", 0, "A", ("", 10, "A"))
這對應於:
ID 為
"1abc"的 Structure。ID 為
0的 Model。ID 為
"A"的 Chain。ID 為
("", 10, "A")的 Residue。
Residue ID 表示殘基不是雜殘基(也不是水),因為它具有空白的雜質欄位,它的序列識別碼為 10,且它的插入碼為 "A"。
若要取得實體的 ID,請使用 get_id 方法。
>>> entity.get_id()
您可以使用 has_id 方法檢查實體是否具有指定 ID 的子系。
>>> entity.has_id(entity_id)
實體的長度等於其子系的數量。
>>> nr_children = len(entity)
可以從父系實體刪除、重新命名、新增等等子系實體,但這不包括任何健全檢查(例如,可以將兩個具有相同 ID 的殘基新增到一條鏈)。這確實應該透過包含完整性檢查的友善 Decorator 類別來完成,但如果您想使用原始介面,可以查看程式碼 (Entity.py)。
Structure
Structure 物件位於階層的頂層。其 ID 是使用者提供的字串。Structure 包含多個 Model 子系。大多數晶體結構(但不是全部)都包含單一模型,而 NMR 結構通常由多個模型組成。大型分子晶體結構中的無序也可能導致多個模型。
Model
Model 物件的 ID 是一個整數,它是從剖析檔案中模型的位置衍生而來(它們會自動從 0 開始編號)。晶體結構通常只有一個模型(ID 為 0),而 NMR 檔案通常有多個模型。雖然許多 PDB 剖析器假設只有一個模型,但 Bio.PDB 中的 Structure 類別的設計使得它可以輕鬆處理有多個模型的 PDB 檔案。
例如,若要從 Structure 物件取得第一個模型,請使用:
>>> first_model = structure[0]
Model 物件會儲存 Chain 子系的清單。
Chain
Chain 物件的 ID 是從 PDB/mmCIF 檔案中的鏈識別碼衍生而來,並且是一個單一字元(通常是字母)。Model 物件中的每個 Chain 都具有唯一的 ID。例如,若要從 Model 物件取得識別碼為「A」的 Chain 物件,請使用:
>>> chain_A = model["A"]
Chain 物件會儲存 Residue 子系的清單。
Residue
殘基 ID 是一個包含三個元素的元組:
雜質欄位 (hetfield):這是:
在水分子的情況下為
'W';以
'H_'開頭,接著是其他雜原子殘基的名稱(例如,葡萄糖分子的情况為'H_GLC');標準胺基酸和核酸則為空白。
此方案的採用原因詳述於 相關問題 章節。
序列識別符(resseq),一個整數,描述殘基在鏈中的位置(例如,100);
插入碼(icode);一個字串,例如 'A'。插入碼有時用於保留特定的理想殘基編號方案。例如,一個 Ser 80 插入突變體(例如,插入在 Thr 80 和 Asn 81 殘基之間)可能具有以下序列識別符和插入碼:Thr 80 A、Ser 80 B、Asn 81。這樣,殘基編號方案會與野生型結構保持一致。
因此,上述葡萄糖殘基的 id 將為 (’H_GLC’, 100, ’A’)。如果雜原子標記和插入碼為空白,則可以單獨使用序列識別符。
# Full id
>>> residue = chain[(" ", 100, " ")]
# Shortcut id
>>> residue = chain[100]
使用雜原子標記的原因是,許多 PDB 檔案對胺基酸、雜原子殘基或水使用相同的序列識別符,如果沒有使用雜原子標記,則會產生明顯的問題。
不出所料,一個 Residue 物件會儲存一組 Atom 子物件。它還包含一個字串,用於指定殘基名稱(例如“ASN”)和殘基的片段識別符(X-PLOR 用戶非常熟悉,但未在 SMCRA 資料結構的建構中使用)。
讓我們來看一些例子。插入碼為空白的 Asn 10 的殘基 id 會是 (’ ’, 10, ’ ’)。水分子 10 的殘基 id 會是 (’W’, 10, ’ ’)。一個序列識別符為 10 的葡萄糖分子(殘基名稱為 GLC 的雜原子殘基)的殘基 id 會是 (’H_GLC’, 10, ’ ’)。如此一來,三個殘基(具有相同的插入碼和序列識別符)可以成為同一鏈的一部分,因為它們的殘基 id 是不同的。
在大多數情况下,hetflag 和插入碼欄位將為空白,例如 (’ ’, 10, ’ ’)。在這些情况下,可以使用序列識別符作為完整 id 的捷徑。
# use full id
>>> res10 = chain[(" ", 10, " ")]
# use shortcut
>>> res10 = chain[10]
鏈物件中的每個 Residue 物件都應具有唯一的 id。然而,無序的殘基會以特殊的方式處理,如 點突變 章節所述。
一個 Residue 物件有多個額外的方法
>>> residue.get_resname() # returns the residue name, e.g. "ASN"
>>> residue.is_disordered() # returns 1 if the residue has disordered atoms
>>> residue.get_segid() # returns the SEGID, e.g. "CHN1"
>>> residue.has_id(name) # test if a residue has a certain atom
您可以使用 is_aa(residue) 來測試一個 Residue 物件是否為胺基酸。
Atom
Atom 物件儲存與原子相關的資料,且沒有子物件。一個原子的 id 是它的原子名稱(例如,Ser 殘基的側鏈氧為“OG”)。一個 Atom id 需要在一個 Residue 中是唯一的。再次強調,對於無序原子會做出例外處理,如 無序原子 章節所述。
原子 id 只是原子名稱(例如 ’CA’)。實際上,原子名稱是透過移除 PDB 檔案中原子名稱的所有空格來建立的。
然而,在 PDB 檔案中,空格可能是原子名稱的一部分。通常,鈣原子會被稱為 ’CA..’,以便與 C\(\alpha\) 原子(稱為 ’.CA.’)區分開來。在移除空格會產生問題的情况下(即,在同一個殘基中有兩個名為 ’CA’ 的原子),則會保留空格。
在 PDB 檔案中,原子名稱由 4 個字元組成,通常帶有前導和尾隨空格。通常可以為了方便使用而移除這些空格(例如,胺基酸 C\(\alpha\) 原子在 PDB 檔案中被標記為“.CA.”,其中點表示空格)。為了生成原子名稱(因此也是原子 id),會移除空格,除非這會在一個 Residue 中導致名稱衝突(即,兩個 Atom 物件具有相同的原子名稱和 id)。在後一種情况下,會嘗試使用包含空格的原子名稱。例如,當一個殘基包含名為“.CA.”和“CA..”的原子時,可能會發生這種情況,儘管這種情況不太可能發生。
儲存的原子資料包括原子名稱、原子坐標(包括標準差,如果存在)、B 因子(包括各向異性 B 因子和標準差,如果存在)、altloc 指定符和包含空格的完整原子名稱。PDB 檔案中偶爾指定的較少使用的項目,如原子元素編號或原子電荷則不會儲存。
若要操作原子坐標,請使用 Atom 物件的 transform 方法。使用 set_coord 方法直接指定原子坐標。
一個 Atom 物件具有以下額外的方法
>>> a.get_name() # atom name (spaces stripped, e.g. "CA")
>>> a.get_id() # id (equals atom name)
>>> a.get_coord() # atomic coordinates
>>> a.get_vector() # atomic coordinates as Vector object
>>> a.get_bfactor() # isotropic B factor
>>> a.get_occupancy() # occupancy
>>> a.get_altloc() # alternative location specifier
>>> a.get_sigatm() # standard deviation of atomic parameters
>>> a.get_siguij() # standard deviation of anisotropic B factor
>>> a.get_anisou() # anisotropic B factor
>>> a.get_fullname() # atom name (with spaces, e.g. ".CA.")
為了表示原子坐標,會使用 siguij、各向異性 B 因子和 sigatm Numpy 陣列。
get_vector 方法會傳回 Atom 物件的坐標的 Vector 物件表示,讓您可以在原子坐標上執行向量運算。Vector 實作了完整的 3D 向量運算、矩陣乘法(左乘和右乘)和一些進階的旋轉相關運算。
作為 Bio.PDB 的 Vector 模組功能的範例,假設您想要找出 Gly 殘基的 C\(\beta\) 原子的位置,如果它有的話。將 Gly 殘基的 N 原子沿著 C\(\alpha\)-C 鍵旋轉 -120 度,大致會將其置於虛擬 C\(\beta\) 原子的位置。以下是如何使用 Vector 模組的 rotaxis 方法(可用於構建繞特定軸旋轉的旋轉)來完成此操作的方法
# get atom coordinates as vectors
>>> n = residue["N"].get_vector()
>>> c = residue["C"].get_vector()
>>> ca = residue["CA"].get_vector()
# center at origin
>>> n = n - ca
>>> c = c - ca
# find rotation matrix that rotates n
# -120 degrees along the ca-c vector
>>> rot = rotaxis(-pi * 120.0 / 180.0, c)
# apply rotation to ca-n vector
>>> cb_at_origin = n.left_multiply(rot)
# put on top of ca atom
>>> cb = cb_at_origin + ca
此範例顯示,有可能對原子資料執行一些相當複雜的向量運算,這可能非常有用。除了所有常見的向量運算(叉積(使用 **),和點積(使用 *)、角度、範數等)和上述的 rotaxis 函數外,Vector 模組還具有將一個向量旋轉 (rotmat) 或反射 (refmat) 到另一個向量之上的方法。
從結構中提取特定的 Atom/Residue/Chain/Model
以下是一些範例
>>> model = structure[0]
>>> chain = model["A"]
>>> residue = chain[100]
>>> atom = residue["CA"]
請注意,您可以使用捷徑
>>> atom = structure[0]["A"][100]["CA"]
無序
Bio.PDB 可以處理無序原子和點突變(即,在相同位置的 Gly 和 Ala 殘基)。
一般方法
應從兩個角度處理無序:原子和殘基的角度。一般而言,我們試圖封裝所有由無序引起的複雜性。如果您只想迴圈遍歷所有 C\(\alpha\) 原子,您不會在意某些殘基是否有無序的側鏈。另一方面,也應該可以在資料結構中完全表示無序。因此,無序原子或殘基會儲存在特殊的物件中,這些物件的行為就像沒有無序一樣。這是透過僅表示無序原子或殘基的子集來完成的。選取哪個子集(例如,使用 Ser 殘基的兩個無序 OG 側鏈原子位置中的哪一個)可以由使用者指定。
無序原子
無序原子由普通的 Atom 物件表示,但所有代表相同物理原子的 Atom 物件都會儲存在 DisorderedAtom 物件中(請參閱 圖 3)。DisorderedAtom 物件中的每個 Atom 物件都可以使用其 altloc 指定符進行唯一索引。預設情况下,DisorderedAtom 物件會將所有未捕獲的方法呼叫轉發到選取的 Atom 物件,即代表具有最高佔據率的原子的物件。使用者當然可以使用其 altloc 指定符來變更選取的 Atom 物件。如此一來,可以正確表示原子無序,而不會有太多的額外複雜性。換句話說,如果您對原子無序不感興趣,則不會受到它的困擾。
每個無序原子都有一個特徵的 altloc 識別符。您可以指定一個 DisorderedAtom 物件應表現得像與特定 altloc 識別符相關聯的 Atom 物件
>>> atom.disordered_select("A") # select altloc A atom
>>> print(atom.get_altloc())
"A"
>>> atom.disordered_select("B") # select altloc B atom
>>> print(atom.get_altloc())
"B"
無序殘基
常見情況
最常見的情況是殘基包含一個或多個無序原子。這顯然可以透過使用 DisorderedAtom 物件來表示無序原子,並將 DisorderedAtom 物件像普通 Atom 物件一樣儲存在 Residue 物件中來解決。DisorderedAtom 會完全像一個普通原子(實際上是佔據率最高的原子)一樣運作,方法是將所有未捕獲的方法呼叫轉發到它所包含的其中一個 Atom 物件(選定的 Atom 物件)。
點突變
當無序是由於點突變而產生時,就會出現一種特殊情況,也就是說,當晶體中存在多個多肽的點突變體時。在 PDB 結構 1EN2 中可以找到一個例子。
由於這些殘基屬於不同的殘基類型(例如,假設是 Ser 60 和 Cys 60),它們不應像常見情況一樣儲存在單個 Residue 物件中。在這種情況下,每個殘基都由一個 Residue 物件表示,並且兩個 Residue 物件都儲存在一個 DisorderedResidue 物件中(請參閱 圖 3)。
DisorderedResidue 物件會將所有未捕獲的方法轉發到選定的 Residue 物件(預設為最後新增的 Residue 物件),因此其行為就像一個普通的殘基。 DisorderedResidue 物件中的每個 Residue 物件都可以透過其殘基名稱唯一識別。在上面的例子中,殘基 Ser 60 在 DisorderedResidue 物件中的 ID 將為「SER」,而殘基 Cys 60 的 ID 將為「CYS」。使用者可以透過此 ID 選擇 DisorderedResidue 物件中的活動 Residue 物件。
範例:假設一個鏈在位置 10 處有一個點突變,由 Ser 和 Cys 殘基組成。請確保該鏈的殘基 10 的行為像 Cys 殘基。
>>> residue = chain[10]
>>> residue.disordered_select("CYS")
此外,您可以使用 (Disordered)Residue 物件的 get_unpacked_list 方法取得所有 Atom 物件的清單(即所有 DisorderedAtom 物件都會「解包」為其個別的 Atom 物件)。
雜環殘基
相關問題
雜環殘基的一個常見問題是,同一鏈中存在的數個雜環和非雜環殘基共用相同的序列識別符(和插入碼)。因此,為了為每個雜環殘基產生一個唯一的 ID,會以不同的方式處理水和其他雜環殘基。
請記住,Residue 物件的 ID 是元組 (hetfield, resseq, icode)。hetfield 對於胺基酸和核酸為空白(「 」),對於水和其他雜環殘基則為字串。hetfield 的內容解釋如下。
水殘基
水殘基的 hetfield 字串由字母「W」組成。因此,水的一個典型殘基 ID 為(「W」,1,「 」)。
其他雜環殘基
其他雜環殘基的 hetfield 字串以「H_」開頭,後跟殘基名稱。例如,一個殘基名稱為「GLC」的葡萄糖分子,其 hetfield 將為「H_GLC」。其殘基 ID 可能會是 (「H_GLC」,1,「 」)。
分析結構
測量距離
原子的減號運算子已重載,以傳回兩個原子之間的距離。
# Get some atoms
>>> ca1 = residue1["CA"]
>>> ca2 = residue2["CA"]
# Simply subtract the atoms to get their distance
>>> distance = ca1 - ca2
測量角度
使用原子座標的向量表示法,以及 Vector 模組中的 calc_angle 函式
>>> vector1 = atom1.get_vector()
>>> vector2 = atom2.get_vector()
>>> vector3 = atom3.get_vector()
>>> angle = calc_angle(vector1, vector2, vector3)
測量扭轉角
使用原子座標的向量表示法,以及 Vector 模組中的 calc_dihedral 函式
>>> vector1 = atom1.get_vector()
>>> vector2 = atom2.get_vector()
>>> vector3 = atom3.get_vector()
>>> vector4 = atom4.get_vector()
>>> angle = calc_dihedral(vector1, vector2, vector3, vector4)
內部座標 - 距離、角度、扭轉角、距離圖等
蛋白質結構通常以相對於固定原點的 3D XYZ 座標提供,如 PDB 或 mmCIF 檔案所示。internal_coords 模組有助於將此系統轉換為鍵長、角度和二面角,並從中轉換出來。除了支援蛋白質結構上的標準psi、phi、chi 等計算之外,此表示法對於平移和旋轉是不變的,並且實作公開了結構分析的多種好處。
首先在這裡載入一些模組,以供稍後的範例使用
>>> from Bio.PDB.PDBParser import PDBParser
>>> from Bio.PDB.Chain import Chain
>>> from Bio.PDB.internal_coords import *
>>> from Bio.PDB.PICIO import write_PIC, read_PIC, read_PIC_seq
>>> from Bio.PDB.ic_rebuild import write_PDB, IC_duplicate, structure_rebuild_test
>>> from Bio.PDB.SCADIO import write_SCAD
>>> from Bio.Seq import Seq
>>> from Bio.SeqRecord import SeqRecord
>>> from Bio.PDB.PDBIO import PDBIO
>>> import numpy as np
存取二面角、角度和鍵長
我們先從計算結構的內部座標的簡單案例開始
>>> # load a structure as normal, get first chain
>>> parser = PDBParser()
>>> myProtein = parser.get_structure("1a8o", "1A8O.pdb")
>>> myChain = myProtein[0]["A"]
>>> # compute bond lengths, angles, dihedral angles
>>> myChain.atom_to_internal_coordinates(verbose=True)
chain break at THR 186 due to MaxPeptideBond (1.4 angstroms) exceeded
chain break at THR 216 due to MaxPeptideBond (1.4 angstroms) exceeded
1A8O 的鏈斷裂警告會透過移除上面的 verbose=True 選項來抑制。為了避免建立斷裂並允許不切實際的長 N-C 鍵,請覆寫類別變數 MaxPeptideBond,例如
>>> IC_Chain.MaxPeptideBond = 4.0
>>> myChain.internal_coord = None # force re-loading structure data with new cutoff
>>> myChain.atom_to_internal_coordinates(verbose=True)
此時,這些值在鏈和殘基層級都可用。1A8O 的第一個殘基是 HETATM MSE(硒甲硫胺酸),因此我們使用規範名稱或原子指定符來研究下面的殘基 2。在這裡,我們依名稱和依原子順序取得 chi1 二面角和 tau 角,並透過指定原子對來取得 C\(\alpha\)-C\(\beta\) 距離
>>> r2 = myChain.child_list[1]
>>> r2
<Residue ASP het= resseq=152 icode= >
>>> r2ic = r2.internal_coord
>>> print(r2ic, ":", r2ic.pretty_str(), ":", r2ic.rbase, ":", r2ic.lc)
('1a8o', 0, 'A', (' ', 152, ' ')) : ASP 152 : (152, None, 'D') : D
>>> r2chi1 = r2ic.get_angle("chi1")
>>> print(round(r2chi1, 2))
-144.86
>>> r2ic.get_angle("chi1") == r2ic.get_angle("N:CA:CB:CG")
True
>>> print(round(r2ic.get_angle("tau"), 2))
113.45
>>> r2ic.get_angle("tau") == r2ic.get_angle("N:CA:C")
True
>>> print(round(r2ic.get_length("CA:CB"), 2))
1.53
Chain.internal_coord 物件包含著多面體(三個鍵結原子)和二面體(四個鍵結原子)物件的陣列和字典。這些字典使用 AtomKey 物件的元組作為索引;AtomKey 物件捕捉殘基位置、插入碼、1 或 3 個字元的殘基名稱、原子名稱、異構位置和佔有率。
以下我們透過直接索引 Chain 陣列來取得與上述相同的 *chi1* 和 *tau* 角,使用 AtomKey 來索引 Chain 陣列。
>>> myCic = myChain.internal_coord
>>> r2chi1_object = r2ic.pick_angle("chi1")
>>> # or same thing (as for get_angle() above):
>>> r2chi1_object == r2ic.pick_angle("N:CA:CB:CG")
True
>>> r2chi1_key = r2chi1_object.atomkeys
>>> r2chi1_key # r2chi1_key is tuple of AtomKeys
(152_D_N, 152_D_CA, 152_D_CB, 152_D_CG)
>>> r2chi1_index = myCic.dihedraNdx[r2chi1_key]
>>> # or same thing:
>>> r2chi1_index == r2chi1_object.ndx
True
>>> print(round(myCic.dihedraAngle[r2chi1_index], 2))
-144.86
>>> # also:
>>> r2chi1_object == myCic.dihedra[r2chi1_key]
True
>>> # hedra angles are similar:
>>> r2tau = r2ic.pick_angle("tau")
>>> print(round(myCic.hedraAngle[r2tau.ndx], 2))
113.45
在 Chain 層級取得鍵長數據會比較複雜(且不建議)。如此處所示,多個多面體將在不同位置共享單一鍵。
>>> r2CaCb = r2ic.pick_length("CA:CB") # returns list of hedra containing bond
>>> r2CaCb[0][0].atomkeys
(152_D_CB, 152_D_CA, 152_D_C)
>>> print(round(myCic.hedraL12[r2CaCb[0][0].ndx], 2)) # position 1-2
1.53
>>> r2CaCb[0][1].atomkeys
(152_D_N, 152_D_CA, 152_D_CB)
>>> print(round(myCic.hedraL23[r2CaCb[0][1].ndx], 2)) # position 2-3
1.53
>>> r2CaCb[0][2].atomkeys
(152_D_CA, 152_D_CB, 152_D_CG)
>>> print(round(myCic.hedraL12[r2CaCb[0][2].ndx], 2)) # position 1-2
1.53
請改用 Residue 層級的 set_length 函式。
測試結構的完整性
當重建結構時,遺失的原子和其他問題可能會導致問題。使用 structure_rebuild_test 來快速判斷結構是否具有足夠的數據以進行乾淨的重建。加入 verbose=True 和/或檢查結果字典以取得更多詳細資訊。
>>> # check myChain makes sense (can get angles and rebuild same structure)
>>> resultDict = structure_rebuild_test(myChain)
>>> resultDict["pass"]
True
修改和重建結構
最好使用殘基層級的 set_angle 和 set_length 功能來修改內部座標,而不是直接存取 Chain 結構。雖然直接修改多面體角度是安全的,但如上所述,鍵長會出現在多個重疊的多面體中,而這會由 set_length 處理。當應用於二面角時,set_angle 會將結果包裝到 +/-180 度,並同時旋轉相鄰的二面體(例如異白胺酸 *chi1* 角的兩個鍵 - 這可能正是您想要的)。
>>> # rotate residue 2 chi1 angle by -120 degrees
>>> r2ic.set_angle("chi1", r2chi1 - 120.0)
>>> print(round(r2ic.get_angle("chi1"), 2))
95.14
>>> r2ic.set_length("CA:CB", 1.49)
>>> print(round(myCic.hedraL12[r2CaCb[0][0].ndx], 2)) # Cb-Ca-C position 1-2
1.49
從內部座標重建結構只需要簡單呼叫 internal_to_atom_coordinates()。
>>> myChain.internal_to_atom_coordinates()
>>> # just for proof:
>>> myChain.internal_coord = None # all internal_coord data removed, only atoms left
>>> myChain.atom_to_internal_coordinates() # re-generate internal coordinates
>>> r2ic = myChain.child_list[1].internal_coord
>>> print(round(r2ic.get_angle("chi1"), 2)) # show measured values match what was set above
95.14
>>> print(round(myCic.hedraL23[r2CaCb[0][1].ndx], 2)) # N-Ca-Cb position 2-3
1.49
可以像平常一樣使用 PDBIO 寫入產生的結構。
write_PDB(myProtein, "myChain.pdb")
# or just the ATOM records without headers:
io = PDBIO()
io.set_structure(myProtein)
io.save("myChain2.pdb")
蛋白質內部座標 (.pic) 檔案和預設值
在 PICIO 模組中定義了一種檔案格式,用於將蛋白質鏈描述為相對於初始座標的多面體和二面體。除了殘基序列資訊(例如 ('1A8O', 0, 'A', (' ', 153, ' ')) ILE)之外,檔案的所有部分都是可選的,如果未指定且使用 defaults=True 選項呼叫 read_PIC,則會使用預設值填入。預設值是根據 2019 年 9 月的 Dunbrack cullpdb_pc20_res2.2_R1.0 計算得出。
這裡我們將 'myChain' 寫成內部座標規範的 .pic 檔案,然後將其讀回為 'myProtein2'。
# write chain as 'protein internal coordinates' (.pic) file
write_PIC(myProtein, "myChain.pic")
# read .pic file
myProtein2 = read_PIC("myChain.pic")
由於所有內部座標值都可以替換為預設值,因此提供 PICIO.read_PIC_seq 作為一個實用函式,以便從輸入序列建立有效的(大部分為螺旋狀的)預設結構。
# create default structure for random sequence by reading as .pic file
myProtein3 = read_PIC_seq(
SeqRecord(
Seq("GAVLIMFPSTCNQYWDEHKR"),
id="1RND",
description="my random sequence",
)
)
myProtein3.internal_to_atom_coordinates()
write_PDB(myProtein3, "myRandom.pdb")
當從內部座標產生結構時,探討例如 *omega* 角 (180.0)、多面體角度和/或鍵長所需的準確性可能會很有趣。write_PIC 的 picFlags 選項允許選擇要寫入 .pic 檔案的數據,而不是保持未指定以取得預設值,進而實現此目的。
可以進行各種組合,並提供一些預設設定,例如 classic 將只把 *psi、phi、tau*、脯胺酸 *omega* 和側鏈 *chi* 角寫入 .pic 檔案。
write_PIC(myProtein, "myChain.pic", picFlags=IC_Residue.pic_flags.classic)
myProtein2 = read_PIC("myChain.pic", defaults=True)
存取全原子 AtomArray
在 atom_to_internal_coordinates 的早期步驟中,Biopython Atom 物件中的所有 3D XYZ 座標都會移動到 Chain 類別中的單個大型陣列,並被替換為該陣列中的 Numpy '視圖'。存取 Biopython Atom 座標的軟體不受影響,但新的陣列可能會為未來的工作提供效率。
與 Atom XYZ 座標不同,AtomArray 座標是同質的,表示它們是像 [ x y z 1.0] 這樣的陣列,其中 1.0 是第四個元素。這有助於在整個 internal_coords 模組中使用組合的平移和旋轉矩陣進行有效轉換。有一個對應的 AtomArrayIndex 字典,將 AtomKeys 對應到它們的座標。
在這裡,我們示範從陣列中讀取特定 C\(\beta\) 原子的座標,然後顯示修改陣列值會同時修改 Atom 物件。
>>> # access the array of all atoms for the chain, e.g. r2 above is residue 152 C-beta
>>> r2_cBeta_index = myChain.internal_coord.atomArrayIndex[AtomKey("152_D_CB")]
>>> r2_cBeta_coords = myChain.internal_coord.atomArray[r2_cBeta_index]
>>> print(np.round(r2_cBeta_coords, 2))
[-0.75 -1.18 -0.51 1. ]
>>> # the Biopython Atom coord array is now a view into atomArray, so
>>> assert r2_cBeta_coords[1] == r2["CB"].coord[1]
>>> r2_cBeta_coords[1] += 1.0 # change the Y coord 1 angstrom
>>> assert r2_cBeta_coords[1] == r2["CB"].coord[1]
>>> # they are always the same (they share the same memory)
>>> r2_cBeta_coords[1] -= 1.0 # restore
請注意,很容易「破壞」原子座標陣列和鏈原子陣列之間的視圖連結。當直接修改原子座標時,請使用逐元素複製的語法來避免這種情況。
# use these:
myAtom1.coord[:] = myAtom2.coord
myAtom1.coord[...] = myAtom2.coord
myAtom1.coord[:] = [1, 2, 3]
for i in range(3):
myAtom1.coord[i] = myAtom2.coord[i]
# do not use:
myAtom1.coord = myAtom2.coord
myAtom1.coord = [1, 2, 3]
使用 atomArrayIndex 和對 AtomKey 類別的了解,使我們能夠建立 Numpy '選擇器',如下所示,以僅提取 C\(\alpha\) 原子座標的陣列。
>>> # create a selector to filter just the C-alpha atoms from the all atom array
>>> atmNameNdx = AtomKey.fields.atm
>>> aaI = myChain.internal_coord.atomArrayIndex
>>> CaSelect = [aaI.get(k) for k in aaI.keys() if k.akl[atmNameNdx] == "CA"]
>>> # now the ordered array of C-alpha atom coordinates is:
>>> CA_coords = myChain.internal_coord.atomArray[CaSelect]
>>> # note this uses Numpy fancy indexing, so CA_coords is a new copy
>>> # (if you modify it, the original atomArray is unaffected)
距離圖
atomArray 的一個好處是,從它產生距離圖只需要一行 Numpy 程式碼。
np.linalg.norm(atomArray[:, None, :] - atomArray[None, :, :], axis=-1)
儘管簡短,但這個慣用語可能難以記住,並且以上述形式產生的是所有原子的距離,而不是可能想要的經典 C\(\alpha\) 圖。distance_plot 方法會封裝上面的程式碼行,並接受一個可選的選擇器,如上一節中定義的 CaSelect。請參閱 圖 4。
# create a C-alpha distance plot
caDistances = myChain.internal_coord.distance_plot(CaSelect)
# display with e.g. MatPlotLib:
import matplotlib.pyplot as plt
plt.imshow(caDistances, cmap="hot", interpolation="nearest")
plt.show()
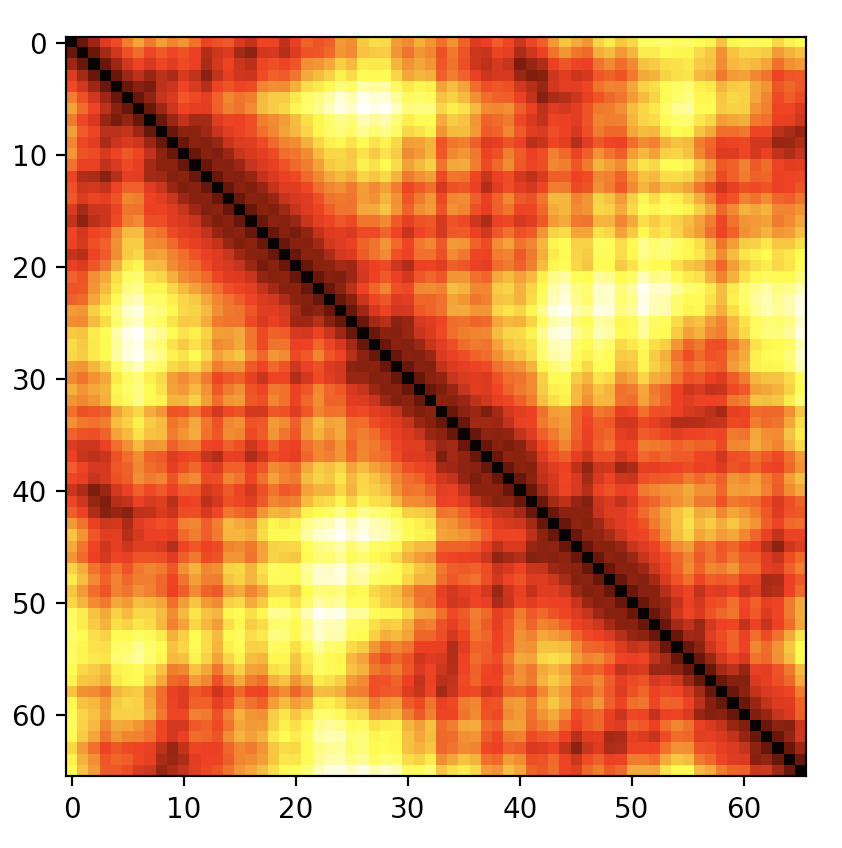
圖 4 PDB 檔案 1A8O (HIV 衣殼 C 端結構域) 的 C-alpha 距離圖
從距離圖建構結構
全原子距離圖是蛋白質結構的另一種表示形式,它也不受平移和旋轉的影響,但缺乏手性資訊(鏡像結構將產生相同的距離圖)。透過將距離矩陣與每個二面角的符號結合起來,就有可能重新生成內部座標。
這項工作使用 Blue 開發的方程式,即 Hedronometer,在 https://math.stackexchange.com/a/49340/409 中討論,並在 http://daylateanddollarshort.com/mathdocs/Heron-like-Results-for-Tetrahedral-Volume.pdf 中進一步討論。
首先,我們從 'myChain' 中提取距離和手性值。
>>> ## create the all-atom distance plot
>>> distances = myCic.distance_plot()
>>> ## get the signs of the dihedral angles
>>> chirality = myCic.dihedral_signs()
我們需要一個與 'myChain' 匹配的有效數據結構才能正確重建它;在一般情況下使用上面的 read_PIC_seq 是可行的,但此處使用的 1A8O 範例有一些 ALTLOC 複雜性,而僅有序列不會產生這種複雜性。為了示範,最簡單的方法是簡單地複製 'myChain' 結構,但是我們將所有原子和內部座標鏈陣列設定為 0(僅用於示範),以確保沒有任何數據從原始結構傳遞過來。
>>> ## get new, empty data structure : copy data structure from myChain
>>> myChain2 = IC_duplicate(myChain)[0]["A"]
>>> cic2 = myChain2.internal_coord
>>> ## clear the new atomArray and di/hedra value arrays, just for proof
>>> cic2.atomArray = np.zeros((cic2.AAsiz, 4), dtype=np.float64)
>>> cic2.dihedraAngle[:] = 0.0
>>> cic2.hedraAngle[:] = 0.0
>>> cic2.hedraL12[:] = 0.0
>>> cic2.hedraL23[:] = 0.0
這種方法是從距離圖數據重新生成內部座標,然後如上所示從內部座標生成原子座標。為了將最終產生的結構放置在與起始結構相同的座標空間中,我們僅將 'myChain' 的鏈開頭的頭三個 N-C\(\alpha\)-C 原子的座標複製到 'myChain2' 結構(這僅在最後示範等效性時需要)。
>>> ## copy just the first N-Ca-C coords so structures will superimpose:
>>> cic2.copy_initNCaCs(myChain.internal_coord)
distance_to_internal_coordinates 常式需要目標結構的每個二面體六個原子間距離的陣列。方便常式 distplot_to_dh_arrays 會根據需要從先前產生的距離矩陣中提取這些值,並且可以使用用戶方法替換,以將這些數據寫入 Chain.internal_coords 物件中的陣列。
>>> ## copy distances to chain arrays:
>>> cic2.distplot_to_dh_arrays(distances, chirality)
>>> ## compute angles and dihedral angles from distances:
>>> cic2.distance_to_internal_coordinates()
以下步驟會從新產生的 'myChain2' 內部座標生成原子座標,然後使用 Numpy allclose 常式來確認所有值都符合優於 PDB 檔案解析度的標準。
>>> ## generate XYZ coordinates from internal coordinates:
>>> myChain2.internal_to_atom_coordinates()
>>> ## confirm result atomArray matches original structure:
>>> np.allclose(cic2.atomArray, myCic.atomArray)
True
請注意,此程序不會使用整個距離矩陣,而只會使用每個二面角的四個原子之間的六個局部距離。
疊加殘基及其鄰域
internal_coords 模組依賴於在不同坐標空間之間轉換原子坐標,以進行扭轉角的計算和結構的重建。每個二面角都有一個坐標空間轉換,將其第一個原子放置在 XZ 平面上,第二個原子放置在原點,第三個原子放置在 +Z 軸上,以及一個相應的反向轉換,將其返回到原始結構中的坐標。這些轉換矩陣可供使用,如下所示。通過明智地選擇參考二面角,可以跨多個蛋白質結構研究和視覺化成對和更高階的殘基相互作用,例如 圖 5。
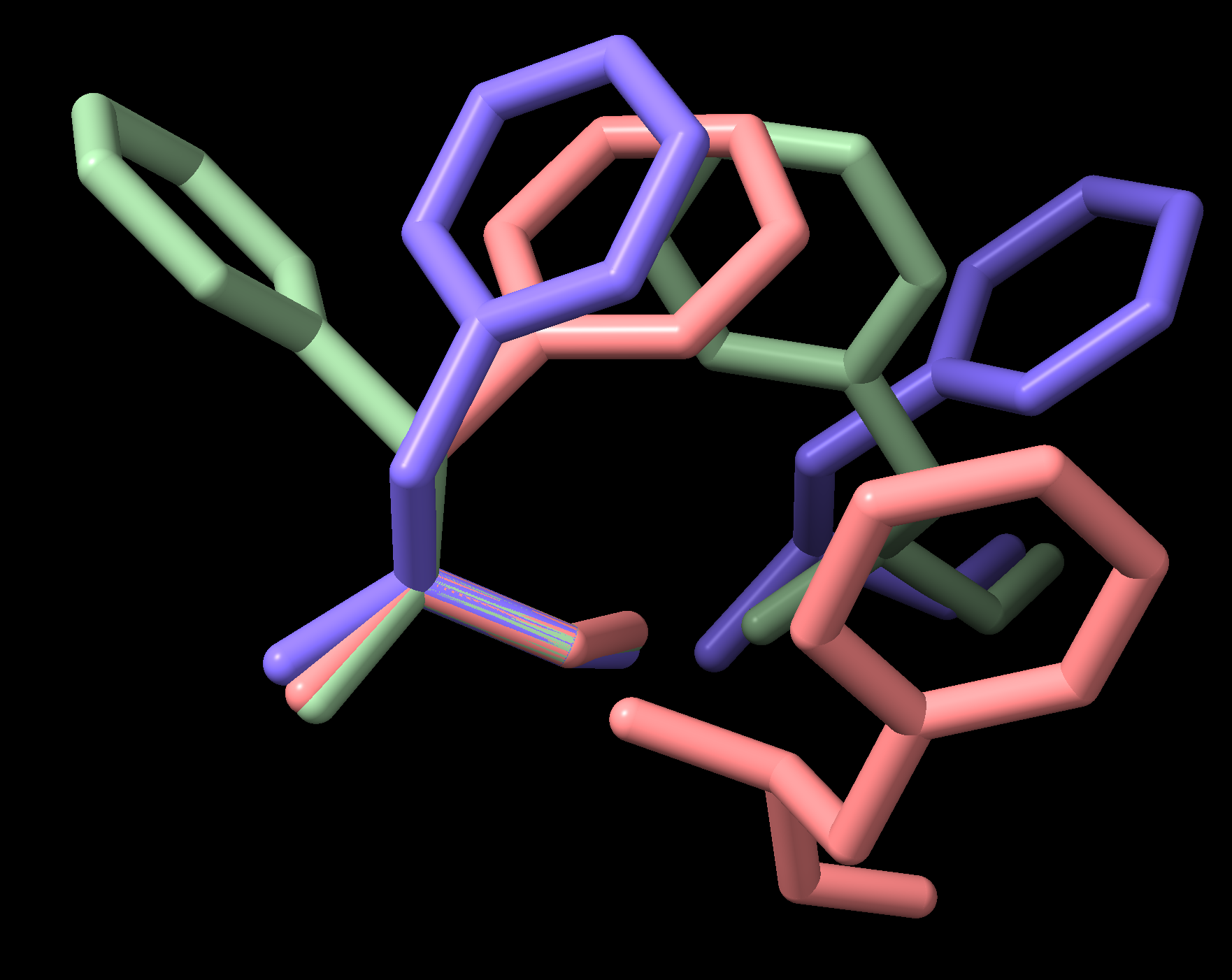
圖 5 PDB 文件 3PBL(人類多巴胺 D3 受體)中相鄰的苯丙氨酸側鏈
此範例將鏈中每個 PHE 殘基疊加在其 N-C\(\alpha\)-C\(\beta\) 原子上,並以簡單示範方式呈現鏈中所有 PHE 在各自坐標空間中的情況。更實際地探索成對側鏈相互作用將檢查結構的數據集,並篩選相關文獻中討論的相互作用類別。
# superimpose all phe-phe pairs - quick hack just to demonstrate concept
# for analyzing pairwise residue interactions. Generates PDB ATOM records
# placing each PHE at origin and showing all other PHEs in environment
## shorthand for key variables:
cic = myChain.internal_coord
resNameNdx = AtomKey.fields.resname
aaNdx = cic.atomArrayIndex
## select just PHE atoms:
pheAtomSelect = [aaNdx.get(k) for k in aaNdx.keys() if k.akl[resNameNdx] == "F"]
aaF = cic.atomArray[pheAtomSelect] # numpy fancy indexing makes COPY not view
for ric in cic.ordered_aa_ic_list: # internal_coords version of get_residues()
if ric.lc == "F": # if PHE, get transform matrices for chi1 dihedral
chi1 = ric.pick_angle("chi1") # N:CA:CB:CG space has C-alpha at origin
cst = np.transpose(chi1.cst) # transform TO chi1 space
# rcst = np.transpose(chi1.rcst) # transform FROM chi1 space (not needed here)
cic.atomArray[pheAtomSelect] = aaF.dot(cst) # transform just the PHEs
for res in myChain.get_residues(): # print PHEs in new coordinate space
if res.resname in ["PHE"]:
print(res.internal_coord.pdb_residue_string())
cic.atomArray[pheAtomSelect] = aaF # restore coordinate space from copy
3D 列印蛋白質結構
OpenSCAD (https://openscad.org) 是一種用於建立實體 3D CAD 物件的語言。從內部坐標構建蛋白質結構的演算法在 OpenSCAD 中提供,其中包含描述結構的數據,這樣可以產生適用於 3D 列印的模型。雖然其他軟體可以產生 STL 數據作為 3D 列印的渲染選項(例如 Chimera,https://www.cgl.ucsf.edu/chimera/),但這種方法會產生球體和圓柱體作為輸出,因此更適合對 3D 列印蛋白質結構進行修改。可以在 OpenSCAD 程式碼中選擇單個殘基和鍵進行特殊處理,例如透過尺寸突出顯示或在特定位置添加可旋轉的鍵(有關範例,請參閱https://www.thingiverse.com/thing:3957471)。
# write OpenSCAD program of spheres and cylinders to 3d print myChain backbone
## set atom load filter to accept backbone only:
IC_Residue.accept_atoms = IC_Residue.accept_backbone
## set chain break cutoff very high to bridge missing residues with long bonds
IC_Chain.MaxPeptideBond = 4.0
## delete existing data to force re-read of all atoms with attributes set above:
myChain.internal_coord = None
write_SCAD(myChain, "myChain.scad", scale=10.0)
internal_coords 控制屬性
在 internal_coords 類別中,有一些控制屬性可用於修改或篩選在計算內部坐標時的數據。這些屬性列在表 Bio.PDB.internal_coords 中的控制屬性。 中。
類別 |
屬性 |
預設值 |
效果 |
|---|---|---|---|
AtomKey |
d2h |
False |
若為 True,則將 D 原子轉換為 H 原子 |
IC_Chain |
MaxPeptideBond |
1.4 |
不含鏈斷裂的最大 C-N 長度;使其較大以連接 3D 模型中缺失的殘基 |
IC_Residue |
accept_atoms |
主鏈、氫原子 |
覆寫以移除部分或所有側鏈、H、D |
IC_Residue |
accept_resnames |
CYG, YCM, UNK |
要處理的 HETATM 的 3 字母名稱,除非添加到 ic_data.py,否則僅處理骨幹 |
IC_Residue |
gly_Cbeta |
False |
覆寫以根據資料庫平均值產生 Gly C\(\beta\) 原子 |
確定原子間接觸
使用 NeighborSearch 來執行鄰近查詢。鄰近查詢是使用以 C 編寫的 KD 樹模組完成的(請參閱 Bio.PDB.kdtrees 模組中的 KDTree 類別),使其速度非常快。它還包括一種快速方法,可以找到彼此在一定距離內的所有點對。
疊加兩個結構
使用 Superimposer 物件來疊加兩個坐標集。此物件計算旋轉和平移矩陣,以這種方式旋轉兩個原子列表使其彼此疊加,從而最小化其 RMSD。當然,這兩個列表需要包含相同數量的原子。Superimposer 物件也可以將旋轉/平移應用於原子列表。旋轉和平移以元組形式儲存在 Superimposer 物件的 rotran 屬性中(請注意,旋轉是右乘!)。RMSD 儲存在 rmsd 屬性中。
Superimposer 使用的演算法來自 Golub & Van Loan [Golub1989],並使用奇異值分解(這是在一般的 Bio.SVDSuperimposer 模組中實作)。
範例
>>> sup = Superimposer()
# Specify the atom lists
# 'fixed' and 'moving' are lists of Atom objects
# The moving atoms will be put on the fixed atoms
>>> sup.set_atoms(fixed, moving)
# Print rotation/translation/rmsd
>>> print(sup.rotran)
>>> print(sup.rms)
# Apply rotation/translation to the moving atoms
>>> sup.apply(moving)
要根據活性位點疊加兩個結構,請使用活性位點原子來計算旋轉/平移矩陣(如上所述),並將其應用於整個分子。
計算半球暴露
半球暴露 (HSE) 是一種新的二維溶劑暴露度量 [Hamelryck2005]。基本上,它計算殘基周圍 C\(\alpha\) 原子在其側鏈方向和相反方向(在 13 Å 的半徑內)的數量。儘管它很簡單,但它優於許多其他溶劑暴露度量。
HSE 有兩種形式:HSE\(\alpha\) 和 HSE\(\beta\)。前者僅使用 C\(\alpha\) 原子位置,而後者使用 C\(\alpha\) 和 C\(\beta\) 原子位置。HSE 度量由 HSExposure 類別計算,該類別也可以計算接觸數。後者類別具有返回字典的方法,這些字典將 Residue 物件對應到其相應的 HSE\(\alpha\)、HSE\(\beta\) 和接觸數值。
範例
>>> model = structure[0]
>>> hse = HSExposure()
# Calculate HSEalpha
>>> exp_ca = hse.calc_hs_exposure(model, option="CA3")
# Calculate HSEbeta
>>> exp_cb = hse.calc_hs_exposure(model, option="CB")
# Calculate classical coordination number
>>> exp_fs = hse.calc_fs_exposure(model)
# Print HSEalpha for a residue
>>> print(exp_ca[some_residue])
確定二級結構
對於此功能,您需要安裝 DSSP(並獲得其授權 – 學術使用免費,請參閱 https://swift.cmbi.umcn.nl/gv/dssp/)。然後使用 DSSP 類別,該類別將 Residue 物件對應到其二級結構(和可存取表面積)。DSSP 代碼列於表 Bio.PDB 中的 DSSP 代碼。 中。請注意,DSSP(程式,因此也因此類別)無法處理多個模型!
代碼 |
二級結構 |
|---|---|
H |
\(\alpha\)-螺旋 |
B |
孤立的 \(\beta\)-橋殘基 |
E |
股 |
G |
3-10 螺旋 |
I |
\(\Pi\)-螺旋 |
T |
轉角 |
S |
彎曲 |
其他 |
DSSP 類別也可用於計算殘基的可存取表面積。但請參閱 計算殘基深度 部分。
計算殘基深度
殘基深度是殘基原子到溶劑可存取表面的平均距離。這是一個相當新的且非常強大的溶劑可存取性參數化方法。對於此功能,您需要安裝 Michel Sanner 的 MSMS 程式 (https://www.scripps.edu/sanner/html/msms_home.html)。然後使用 ResidueDepth 類別。此類別的行為類似於字典,它將 Residue 物件對應到相應的(殘基深度、C\(\alpha\) 深度)元組。C\(\alpha\) 深度是殘基的 C\(\alpha\) 原子到溶劑可存取表面的距離。
範例
>>> model = structure[0]
>>> rd = ResidueDepth(model, pdb_file)
>>> residue_depth, ca_depth = rd[some_residue]
您也可以存取分子表面本身(透過 get_surface 函數),形式為包含表面點的 Numeric Python 陣列。
PDB 檔案中的常見問題
眾所周知,許多 PDB 檔案包含語義錯誤(不是結構本身,而是它們在 PDB 檔案中的表示)。Bio.PDB 嘗試透過兩種方式來處理此問題。PDBParser 物件可以兩種方式運作:限制性方式和寬容性方式,後者是預設方式。
範例
# Permissive parser
>>> parser = PDBParser(PERMISSIVE=1)
>>> parser = PDBParser() # The same (default)
# Strict parser
>>> strict_parser = PDBParser(PERMISSIVE=0)
在寬容狀態(預設)下,明顯包含錯誤的 PDB 檔案會被「修正」(即會遺漏一些殘基或原子)。這些錯誤包括:
具有相同識別碼的多個殘基
具有相同識別碼的多個原子(考慮到 altloc 識別碼)
這些錯誤表示 PDB 檔案中存在實際問題(有關詳細資訊,請參閱 Hamelryck 和 Manderick,2003 [Hamelryck2003A])。在限制性狀態下,包含錯誤的 PDB 檔案會導致發生例外狀況。這有助於找出 PDB 檔案中的錯誤。
然而,有些錯誤會自動修正。通常,每個無序原子都應具有非空白的 altloc 識別碼。但是,有許多結構不符合此慣例,並且同一個原子的兩個無序位置都具有空白和非空白的識別碼。這會自動以正確的方式解讀。
有時,一個結構包含屬於鏈 A 的殘基列表,然後是屬於鏈 B 的殘基,然後又是屬於鏈 A 的殘基,即鏈條被「打斷」。這也會被正確地解讀。
範例
PDBParser/Structure 類別在約 800 個結構(每個結構屬於唯一的 SCOP 超家族)上進行了測試。這大約需要 20 分鐘,或每個結構平均 1.5 秒。剖析包含約 64000 個原子的大型核糖體亞基 (1FKK) 的結構在 1000 MHz 的 PC 上需要 10 秒。
在無法建立明確資料結構的情況下,產生了三個例外。在這三種情況下,可能的原因都是 PDB 檔案中的錯誤,應該加以修正。在這些情況下產生例外,遠比冒著在資料結構中錯誤描述結構的風險要好得多。
重複殘基
一個結構在一個鏈中包含兩個具有相同序列識別碼(resseq 3)和 icode 的胺基酸殘基。經檢查發現,此鏈包含殘基 Thr A3、...、Gly A202、Leu A3、Glu A204。顯然,Leu A3 應該是 Leu A203。結構 1FFK 存在一些類似的情況(例如,包含 Gly B64、Met B65、Glu B65、Thr B67,即殘基 Glu B65 應該是 Glu B66)。
重複原子
結構 1EJG 在 A 鏈的 22 位置包含一個 Ser/Pro 點突變。反過來說,Ser 22 包含一些無序原子。如預期的,屬於 Ser 22 的所有原子都有一個非空白的 altloc 指定符(B 或 C)。Pro 22 的所有原子都有 altloc A,除了 N 原子,其 altloc 為空白。這會產生例外,因為在點突變處的兩個殘基的所有原子都應該具有非空白的 altloc。結果發現,這個原子可能由 Ser 和 Pro 22 共享,因為 Ser 22 缺少 N 原子。同樣,這指向檔案中的問題:N 原子應該同時存在於 Ser 和 Pro 殘基中,並且在兩種情況下都與合適的 altloc 識別碼相關聯。
自動修正
有些錯誤相當常見,並且可以輕鬆修正,而不會有錯誤解讀的風險。這些情況列在下面。
無序原子的空白 altloc
通常,每個無序原子都應該具有非空白的 altloc 識別碼。然而,有許多結構不遵循此慣例,並且對於同一個原子的兩個無序位置具有空白和非空白識別碼。這會自動以正確的方式進行解讀。
斷裂的鏈
有時,一個結構包含屬於鏈 A 的殘基列表,接著是屬於鏈 B 的殘基,然後又是屬於鏈 A 的殘基,即鏈是「斷裂的」。這會正確地解讀。
嚴重錯誤
有時,PDB 檔案無法明確解讀。為了避免猜測和犯錯的風險,會產生例外,並且預期使用者會修正 PDB 檔案。這些情況列在下面。
重複殘基
一個鏈中的所有殘基都應該具有唯一的 id。此 id 是基於以下內容產生的:
序列識別碼 (resseq)。
插入碼 (icode)。
hetfield 字串(水的 “W”,以及其他雜原子殘基的 “H_” 後面跟著殘基名稱)。
在點突變情況下,殘基的殘基名稱(將殘基物件儲存在 DisorderedResidue 物件中)。
如果這沒有產生唯一的 id,則很可能出現問題,並且會產生例外。
重複原子
一個殘基中的所有原子都應該具有唯一的 id。此 id 是基於以下內容產生的:
原子名稱(不帶空格,或在出現問題時帶空格)。
altloc 指定符。
如果這沒有產生唯一的 id,則很可能出現問題,並且會產生例外。
存取蛋白質資料庫
從蛋白質資料庫下載結構
可以使用 PDBList 物件的 retrieve_pdb_file 方法從 PDB(蛋白質資料庫)下載結構。此方法的參數是結構的 PDB 識別碼。
>>> pdbl = PDBList()
>>> pdbl.retrieve_pdb_file("1FAT")
PDBList 類別也可以用作命令列工具
python PDBList.py 1fat
下載的檔案將被命名為 pdb1fat.ent,並儲存在目前的工作目錄中。請注意,retrieve_pdb_file 方法也有一個可選參數 pdir,用於指定要儲存下載的 PDB 檔案的特定目錄。
retrieve_pdb_file 方法還具有一些選項,可以指定用於下載的壓縮格式,以及用於本機解壓縮的程式(預設為 .Z 格式和 gunzip)。此外,可以在建立 PDBList 物件時指定 PDB ftp 站點。預設情況下,使用全球蛋白質資料庫的伺服器(ftp://ftp.wwpdb.org/pub/pdb/data/structures/divided/pdb/)。有關更多詳細資訊,請參閱 API 文件。再次感謝 Kristian Rother 捐贈此模組。
下載整個 PDB
以下命令會將所有 PDB 檔案儲存在 /data/pdb 目錄中
python PDBList.py all /data/pdb
python PDBList.py all /data/pdb -d
此 API 方法稱為 download_entire_pdb。新增 -d 選項會將所有檔案儲存在同一個目錄中。否則,它們會根據其 PDB ID 排序到 PDB 樣式的子目錄中。根據流量,完整下載將需要 2-4 天。
保持 PDB 的本機副本為最新狀態
也可以使用 PDBList 物件來完成。只需建立一個 PDBList 物件(指定 PDB 本機副本所在的目錄),並呼叫 update_pdb 方法
>>> pl = PDBList(pdb="/data/pdb")
>>> pl.update_pdb()
當然,可以將此設定為每週 cronjob,以使本機副本自動保持最新狀態。也可以指定 PDB ftp 站點(請參閱 API 文件)。
PDBList 有一些額外的方法可能會有用。 get_all_obsolete 方法可用於取得所有過時 PDB 條目的列表。 changed_this_week 方法可用於取得在本週新增、修改或過時的條目。有關 PDBList 功能的更多資訊,請參閱 API 文件。
一般問題
Bio.PDB 的測試完善程度如何?
實際上相當完善。Bio.PDB 已在來自 PDB 的近 5500 個結構上進行了廣泛測試 - 所有結構似乎都已正確解析。可以在 Bio.PDB 生物資訊學文章中找到更多詳細資訊。Bio.PDB 已在許多研究專案中被使用/正在被使用,作為一個可靠的工具。事實上,我幾乎每天都在將 Bio.PDB 用於研究目的,並繼續致力於改進它和新增新功能。
它有多快?
在約 800 個結構(每個結構都屬於一個唯一的 SCOP 超家族)上測試了 PDBParser 的效能。這大約需要 20 分鐘,平均每個結構 1.5 秒。解析大型核糖體亞基(1FKK)的結構(包含約 64000 個原子)在 1000 MHz PC 上需要 10 秒。簡而言之:對於許多應用來說,它的速度綽綽有餘。
是否有分子圖形支援?
不是直接支援,主要是因為已經有很多基於 Python 的/了解 Python 的解決方案,可以與 Bio.PDB 一起使用。我的選擇是 Pymol,順便一提(我已成功將其與 Bio.PDB 一起使用,而且 Bio.PDB 很可能很快/有一天會出現特定的 PyMol 模組)。基於 Python 的/了解 Python 的分子圖形解決方案包括:
PyMol: https://pymol.org/
Chimera: https://www.cgl.ucsf.edu/chimera/
CCP4mg: http://www.ccp4.ac.uk/MG/
誰在使用 Bio.PDB?
Bio.PDB 被用於建構 DISEMBL,這是一個預測蛋白質中無序區域的網路伺服器(http://dis.embl.de/)。Bio.PDB 也被用於在 PDB 的蛋白質結構之間進行大規模活性位點相似性搜尋[Hamelryck2003B],並開發了一種新的演算法,用於識別線性二級結構元素 [Majumdar2005]。
從功能和資訊的要求來看,Bio.PDB 也被一些 LPC(大型製藥公司 :-)使用。