BLAST (新)
嘿,大家都很喜歡 BLAST 對吧?我的意思是,天啊,要比較你的序列和已知世界中的其他序列,怎麼可能更簡單呢?但是,當然,本節不是在講 BLAST 有多酷,因為我們已經知道了。它是關於 BLAST 的問題 – 處理大型執行產生的大量數據,以及自動化 BLAST 執行通常會非常困難。
幸運的是,Biopython 的人們非常清楚這一點,所以他們開發了許多工具來處理 BLAST,使事情變得更加容易。本節詳細介紹如何使用這些工具並用它們做有用的事情。
處理 BLAST 可以分為兩個步驟,這兩個步驟都可以在 Biopython 中完成。首先,為您的查詢序列執行 BLAST,並取得一些輸出。其次,在 Python 中解析 BLAST 輸出,以便進行進一步的分析。
您第一次接觸到執行 BLAST 可能是透過 NCBI BLAST 網頁。事實上,有很多方法可以執行 BLAST,可以透過幾種方式進行分類。最重要的區別是在本機(您自己的機器上)執行 BLAST,以及遠端(在另一台機器上,通常是 NCBI 伺服器上)執行 BLAST。我們將在本章開始時,從 Python 腳本中調用 NCBI 線上 BLAST 服務。
透過網際網路執行 BLAST
我們使用 Bio.Blast 模組中的 qblast 函式來呼叫線上版本的 BLAST。
NCBI 指南指出
不要以高於每 10 秒一次的頻率聯絡伺服器。
不要以高於每分鐘一次的頻率輪詢任何單一 RID。
使用 URL 參數 email 和 tool,以便 NCBI 在發生問題時可以聯絡您。
如果提交的搜尋超過 50 次,請在週末或平日東部時間晚上 9 點到凌晨 5 點之間執行腳本。
Blast.qblast 會自動遵循前兩點。為了滿足第三點,請設定 Blast.email 變數(Blast.tool 變數預設已設定為 "biopython")
>>> from Bio import Blast
>>> Blast.tool
'biopython'
>>> Blast.email = "A.N.Other@example.com"
BLAST 參數
qblast 函式有三個非選用參數
第一個參數是要用於搜尋的 BLAST 程式,以小寫字串表示。程式及其選項在 NCBI BLAST 網頁中說明。目前
qblast僅適用於 blastn、blastp、blastx、tblast 和 tblastx。第二個參數指定要搜尋的資料庫。同樣,此選項可在 NCBI 的 BLAST 說明頁面上取得。
第三個參數是包含您的查詢序列的字串。這可以是序列本身、fasta 格式的序列,或是像 GI 編號這樣的識別碼。
qblast 函式還接受許多其他選用參數,這些參數基本上類似於您可以在 BLAST 網頁上設定的不同參數。我們在這裡只會強調其中幾個
url_base參數會設定透過網際網路執行 BLAST 的基本 URL。預設情況下,它會連線到 NCBI,但是可以使用此選項來連線到在雲端中執行的 NCBI BLAST 實例。請參考qblast函式的說明文件,以取得更多詳細資訊。qblast函式可以以各種格式傳回 BLAST 結果,您可以使用選用的format_type關鍵字來選擇:"XML"、"HTML"、"Text"、"XML2"、"JSON2"或"Tabular"。預設值為"XML",因為這是剖析器預期的格式,如下方解析 BLAST 輸出一節所述。expect參數會設定期望值或 e 值閾值。
如需有關選用 BLAST 參數的更多資訊,我們建議您參考 NCBI 自己的說明文件,或內建於 Biopython 中的說明文件
>>> from Bio import Blast
>>> help(Blast.qblast)
請注意,NCBI BLAST 網站上的預設設定與 QBLAST 上的預設設定不太相同。如果您的結果不同,您需要檢查參數(例如,期望值閾值和間隙值)。
例如,如果您有一個想要使用 BLASTN 針對核苷酸資料庫 (nt) 搜尋的核苷酸序列,並且您知道您的查詢序列的 GI 編號,您可以使用
>>> from Bio import Blast
>>> result_stream = Blast.qblast("blastn", "nt", "8332116")
或者,如果我們的查詢序列已在 FASTA 格式的檔案中,我們只需要開啟檔案並將此記錄讀取為字串,並將其用作查詢參數
>>> from Bio import Blast
>>> fasta_string = open("m_cold.fasta").read()
>>> result_stream = Blast.qblast("blastn", "nt", fasta_string)
我們也可以將 FASTA 檔案讀取為 SeqRecord,然後僅提供序列本身
>>> from Bio import Blast
>>> from Bio import SeqIO
>>> record = SeqIO.read("m_cold.fasta", "fasta")
>>> result_stream = Blast.qblast("blastn", "nt", record.seq)
僅提供序列意味著 BLAST 會自動為您的序列指派識別碼。您可能更喜歡在 SeqRecord 物件上呼叫 format 來建立 FASTA 字串(其中將包含現有的識別碼)
>>> from Bio import Blast
>>> from Bio import SeqIO
>>> records = SeqIO.parse("ls_orchid.gbk", "genbank")
>>> record = next(records)
>>> result_stream = Blast.qblast("blastn", "nt", format(record, "fasta"))
如果您將序列儲存在可以使用 Bio.SeqIO 擷取的非 FASTA 檔案格式中,則此方法更有意義(請參閱第 序列輸入/輸出章)。
儲存 BLAST 結果
無論您給 qblast() 函式什麼參數,您都應該以 bytes 資料流的形式傳回結果(預設為 XML 格式)。下一步是將 XML 輸出解析為代表搜尋結果的 Python 物件(解析 BLAST 輸出一節),但是您可能希望先儲存輸出的本機副本。當我對從 BLAST 結果中擷取資訊的程式碼進行除錯時,我發現這特別有用(因為重新執行線上搜尋很慢,並且浪費 NCBI 電腦時間)。
我們需要小心一點,因為我們只能使用 result_stream.read() 來讀取 BLAST 輸出一次 – 再次呼叫 result_stream.read() 會傳回空的 bytes 物件。
>>> with open("my_blast.xml", "wb") as out_stream:
... out_stream.write(result_stream.read())
...
>>> result_stream.close()
執行此操作後,結果將位於檔案 my_blast.xml 中,並且 result_stream 已擷取其所有資料(因此我們已將其關閉)。但是,BLAST 剖析器的 parse 函式(在 解析 BLAST 輸出中說明)會接受檔案類物件,因此我們可以僅開啟儲存的檔案以作為 bytes 輸入
>>> result_stream = open("my_blast.xml", "rb")
既然我們已經將 BLAST 結果重新放入資料流中,我們就準備好對它們做一些事情了,因此這將我們直接帶到剖析章節(請參閱下方解析 BLAST 輸出一節)。您現在可能想跳到那裡 …。
以其他格式取得 BLAST 輸出
透過在呼叫 qblast 時使用 format_type 參數,您可以取得 XML 以外的格式的 BLAST 輸出。以下是讀取 JSON 格式 BLAST 輸出的範例。使用 format_type="JSON2",Blast.qblast 提供的資料將為壓縮的 JSON 格式
>>> from Bio import Blast
>>> from Bio import SeqIO
>>> record = SeqIO.read("m_cold.fasta", "fasta")
>>> result_stream = Blast.qblast("blastn", "nt", record.seq, format_type="JSON2")
>>> data = result_stream.read()
>>> data[:4]
b'PK\x03\x04'
這是 ZIP 檔案魔術數字。
>>> with open("myzipfile.zip", "wb") as out_stream:
... out_stream.write(data)
...
13813
請注意,我們以 bytes 讀寫資料。現在開啟我們建立的 ZIP 檔案
>>> import zipfile
>>> myzipfile = zipfile.ZipFile("myzipfile.zip")
>>> myzipfile.namelist()
['N5KN7UMJ013.json', 'N5KN7UMJ013_1.json']
>>> stream = myzipfile.open("N5KN7UMJ013.json")
>>> data = stream.read()
這些資料是 bytes,因此我們需要將它們解碼以取得字串物件
>>> data = data.decode()
>>> print(data)
{
"BlastJSON": [
{"File": "N5KN7UMJ013_1.json" }
]
}
現在開啟 ZIP 檔案中包含的第二個檔案,以取得 JSON 格式的 BLAST 結果
>>> stream = myzipfile.open("N5KN7UMJ013_1.json")
>>> data = stream.read()
>>> len(data)
145707
>>> data = data.decode()
>>> print(data)
{
"BlastOutput2": {
"report": {
"program": "blastn",
"version": "BLASTN 2.14.1+",
"reference": "Stephen F. Altschul, Thomas L. Madden, Alejandro A. ...
"search_target": {
"db": "nt"
},
"params": {
"expect": 10,
"sc_match": 2,
"sc_mismatch": -3,
"gap_open": 5,
"gap_extend": 2,
"filter": "L;m;"
},
"results": {
"search": {
"query_id": "Query_69183",
"query_len": 1111,
"query_masking": [
{
"from": 797,
"to": 1110
}
],
"hits": [
{
"num": 1,
"description": [
{
"id": "gi|1219041180|ref|XM_021875076.1|",
...
我們可以使用 Python 標準程式庫中的 JSON 剖析器,將 JSON 資料轉換為一般 Python 字典
>>> import json
>>> d = json.loads(data)
>>> print(d)
{'BlastOutput2': {'report': {'program': 'blastn', 'version': 'BLASTN 2.14.1+',
'reference': 'Stephen F. Altschul, Thomas L. Madden, Alejandro A. Schäffer,
Jinghui Zhang, Zheng Zhang, Webb Miller, and David J. Lipman (1997),
"Gapped BLAST and PSI-BLAST: a new generation of protein database search programs",
Nucleic Acids Res. 25:3389-3402.',
'search_target': {'db': 'nt'}, 'params': {'expect': 10, 'sc_match': 2,
'sc_mismatch': -3, 'gap_open': 5, 'gap_extend': 2, 'filter': 'L;m;'},
'results': {'search': {'query_id': 'Query_128889', 'query_len': 1111,
'query_masking': [{'from': 797, 'to': 1110}], 'hits': [{'num': 1,
'description': [{'id': 'gi|1219041180|ref|XM_021875076.1|', 'accession':
'XM_021875076', 'title':
'PREDICTED: Chenopodium quinoa cold-regulated 413 plasma membrane protein 2-like (LOC110697660), mRNA',
'taxid': 63459, 'sciname': 'Chenopodium quinoa'}], 'len': 1173, 'hsps':
[{'num': 1, 'bit_score': 435.898, 'score': 482, 'evalue': 9.02832e-117,
'identity': 473, 'query_from'
...
在本機執行 BLAST
簡介
在本機執行 BLAST(而不是透過網際網路,請參閱透過網際網路執行 BLAST一節)至少有兩個主要優點
在本機執行 BLAST 可能比透過網際網路執行 BLAST 更快;
在本機執行 BLAST 可讓您建立自己的資料庫來搜尋序列。
處理專有或未發表的序列數據可能是本地執行 BLAST 的另一個原因。您可能不被允許重新分發這些序列,因此將它們作為 BLAST 查詢提交給 NCBI 將不是一個可行的選項。
不幸的是,也有一些主要的缺點——安裝所有組件並正確設置需要一些努力
本地 BLAST 需要安裝命令列工具。
本地 BLAST 需要設置(且可能需要保持更新) (大型) BLAST 數據庫。
獨立的 NCBI BLAST+
「新」的 NCBI BLAST+ 套件於 2009 年發布。它取代了舊的 NCBI「傳統」BLAST 套件(請參閱 BLAST 的其他版本)。
本節將簡要展示如何從 Python 中使用這些工具。如果您已經閱讀或嘗試過第 比對工具 節中的比對工具範例,這一切應該看起來相當簡單。首先,我們建構一個命令列字串(就像您在手動執行獨立 BLAST 時在命令列提示符號中輸入的一樣)。然後我們可以從 Python 中執行這個命令。
例如,採用基因核苷酸序列的 FASTA 檔案,您可能想要針對非冗餘 (NR) 蛋白質數據庫執行 BLASTX(翻譯)搜尋。假設您(或您的系統管理員)已下載並安裝 NR 數據庫,您可能會執行
$ blastx -query opuntia.fasta -db nr -out opuntia.xml -evalue 0.001 -outfmt 5
這應該會針對 NR 數據庫執行 BLASTX,使用預期截止值 \(0.001\) 並產生 XML 輸出到指定的檔案(然後我們可以解析它)。在我的電腦上,這大約需要六分鐘——這是一個將輸出儲存到檔案的好理由,以便您可以根據需要重複任何分析。
在 Python 中,我們可以使用 subprocess 模組來建立命令列字串並執行它
>>> import subprocess
>>> cmd = "blastx -query opuntia.fasta -db nr -out opuntia.xml"
>>> cmd += " -evalue 0.001 -outfmt 5"
>>> subprocess.run(cmd, shell=True)
在這個範例中,不應該有來自 BLASTX 到終端機的任何輸出。您可能想要檢查輸出檔案 opuntia.xml 是否已建立。
您可能還記得本教學課程中的先前範例,opuntia.fasta 包含七個序列,因此 BLAST XML 輸出應包含多個結果。因此,請使用 Bio.Blast.parse() 來解析它,如下面第 解析 BLAST 輸出 節中所述。
BLAST 的其他版本
NCBI BLAST+(以 C++ 編寫)於 2009 年首次發布,作為原始 NCBI「傳統」BLAST(以 C 編寫,不再更新)的替代品。您可能還會遇到 華盛頓大學 BLAST (WU-BLAST) 及其後繼者 Advanced Biocomputing BLAST (AB-BLAST,於 2009 年發布,非免費/開源)。這些套件包含命令列工具 wu-blastall 和 ab-blastall,它們模仿了 NCBI「傳統」BLAST 套件中的 blastall。Biopython 目前不提供呼叫這些工具的包裝函式,但應該能夠解析它們的任何 NCBI 相容輸出。
解析 BLAST 輸出
如上所述,BLAST 可以產生各種格式的輸出,例如 XML、HTML 和純文字。最初,Biopython 具有用於 BLAST 純文字和 HTML 輸出的剖析器,因為這些是當時提供的唯一輸出格式。這些剖析器現在已從 Biopython 中移除,因為這些格式的 BLAST 輸出不斷變化,每次都會破壞 Biopython 剖析器。現在,Biopython 可以解析 XML 格式、XML2 格式和表格格式的 BLAST 輸出。本章介紹使用 Bio.Blast.parse 函式解析 XML 和 XML2 格式的 BLAST 輸出。此函式會自動偵測 XML 檔案是 XML 格式還是 XML2 格式。表格格式的 BLAST 輸出可以使用 Bio.Align.parse 函式解析為比對(請參閱 BLAST 或 FASTA 的表格輸出)。
您可以使用各種方式取得 XML 格式的 BLAST 輸出。對於剖析器來說,輸出是如何產生的並不重要,只要它是 XML 格式即可。
您可以按照第 透過網際網路執行 BLAST 節中的說明,使用 Biopython 透過網際網路執行 BLAST。
您可以按照第 在本機執行 BLAST 節中的說明,使用 Biopython 在本機執行 BLAST。
您可以自己在 NCBI 網站上透過網頁瀏覽器執行 BLAST 搜尋,然後儲存結果。您需要在接收結果時選擇 XML 作為格式,並將您獲得的最終 BLAST 頁面(您知道,包含所有有趣結果的那個!)儲存到檔案中。
您也可以在本機執行 BLAST 而不使用 Biopython,並將輸出儲存到檔案中。同樣,您需要在接收結果時選擇 XML 作為格式。
重要的是,您不必使用 Biopython 腳本來擷取資料,才能解析資料。以這些方式之一執行操作後,您需要取得結果的檔案類物件。在 Python 中,檔案類物件或控制代碼只是一種描述任何資訊來源輸入的通用方式,以便可以使用 read() 和 readline() 函式擷取資訊(請參閱第 控制代碼到底是什麼? 節)。
如果您依照上面的程式碼透過腳本與 BLAST 互動,那麼您已經有了 result_stream,這是 BLAST 結果的檔案類物件。例如,使用 GI 編號來執行線上搜尋
>>> from Bio import Blast
>>> result_stream = Blast.qblast("blastn", "nt", "8332116")
如果您以其他方式執行 BLAST,並且在檔案 my_blast.xml 中有 BLAST 輸出(以 XML 格式),您需要做的就是開啟檔案進行讀取(以 bytes 方式)
>>> result_stream = open("my_blast.xml", "rb")
現在我們有了資料串流,我們準備好解析輸出了。解析它的程式碼非常小。如果您預期單一 BLAST 結果(即,您使用單一查詢)
>>> from Bio import Blast
>>> blast_record = Blast.read(result_stream)
或者,如果您有很多結果(即,多個查詢序列)
>>> from Bio import Blast
>>> blast_records = Blast.parse(result_stream)
就像 Bio.SeqIO 和 Bio.Align(請參閱第 序列輸入/輸出 章和 序列比對 章),我們有一對輸入函式 read 和 parse,其中 read 用於當您只有一個物件時,而 parse 用於當您可以有很多物件時的迭代器 – 但我們不是取得 SeqRecord 或 Alignment 物件,而是取得 BLAST 記錄物件。
為了能夠處理 BLAST 檔案可能很大(包含數千個結果)的情況,Blast.parse() 會傳回迭代器。簡單來說,迭代器允許您逐步瀏覽 BLAST 輸出,為每個 BLAST 搜尋結果一次擷取一個 BLAST 記錄
>>> from Bio import Blast
>>> blast_records = Blast.parse(result_stream)
>>> blast_record = next(blast_records)
# ... do something with blast_record
>>> blast_record = next(blast_records)
# ... do something with blast_record
>>> blast_record = next(blast_records)
# ... do something with blast_record
>>> blast_record = next(blast_records)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
# No further records
或者,您可以使用 for 迴圈
>>> for blast_record in blast_records:
... pass # Do something with blast_record
...
但請注意,您只能逐步瀏覽 BLAST 記錄一次。通常,您會從每個 BLAST 記錄中儲存您感興趣的資訊。
或者,您可以將 blast_records 作為清單使用,例如透過索引擷取一個記錄,或在 blast_records 上呼叫 len 或 print。然後剖析器會自動迭代記錄並儲存它們
>>> from Bio import Blast
>>> blast_records = Blast.parse("xml_2222_blastx_001.xml")
>>> len(blast_records) # this causes the parser to iterate over all records
7
>>> blast_records[2].query.description
'gi|5690369|gb|AF158246.1|AF158246 Cricetulus griseus glucose phosphate isomerase (GPI) gene, partial intron sequence'
但如果您的 BLAST 檔案很大,嘗試將它們全部儲存在清單中可能會遇到記憶體問題。
如果您在將 blast_records 作為清單使用之前開始迭代記錄,則剖析器會先將檔案串流重設到資料的開頭,以確保讀取所有記錄。請注意,如果無法將串流重設到開頭,則此操作將會失敗,例如如果資料是遠端讀取的(例如,透過 qblast;請參閱小節 透過網際網路執行 BLAST)。在這些情況下,您可以在迭代之前呼叫 blast_records = blast_records[:] 來明確地將記錄讀取到清單中。讀取記錄後,就可以安全地迭代它們或將它們用作清單。
您可以直接提供檔案名稱,而無需自行開啟檔案
>>> from Bio import Blast
>>> with Blast.parse("my_blast.xml") as blast_records:
... for blast_record in blast_records:
... pass # Do something with blast_record
...
在這種情況下,Biopython 會為您開啟檔案,並在不再需要該檔案時立即關閉它(雖然可以簡單地使用 blast_records = Blast.parse("my_blast.xml"),但它的缺點是檔案可能會開啟的時間比嚴格必要的時間長,從而浪費資源)。
您可以 print 記錄以快速概述其內容
>>> from Bio import Blast
>>> with Blast.parse("my_blast.xml") as blast_records:
... print(blast_records)
...
Program: BLASTN 2.2.27+
db: refseq_rna
Query: 42291 (length=61)
mystery_seq
Hits: ---- ----- ----------------------------------------------------------
# # HSP ID + description
---- ----- ----------------------------------------------------------
0 1 gi|262205317|ref|NR_030195.1| Homo sapiens microRNA 52...
1 1 gi|301171311|ref|NR_035856.1| Pan troglodytes microRNA...
2 1 gi|270133242|ref|NR_032573.1| Macaca mulatta microRNA ...
3 2 gi|301171322|ref|NR_035857.1| Pan troglodytes microRNA...
4 1 gi|301171267|ref|NR_035851.1| Pan troglodytes microRNA...
5 2 gi|262205330|ref|NR_030198.1| Homo sapiens microRNA 52...
6 1 gi|262205302|ref|NR_030191.1| Homo sapiens microRNA 51...
7 1 gi|301171259|ref|NR_035850.1| Pan troglodytes microRNA...
8 1 gi|262205451|ref|NR_030222.1| Homo sapiens microRNA 51...
9 2 gi|301171447|ref|NR_035871.1| Pan troglodytes microRNA...
10 1 gi|301171276|ref|NR_035852.1| Pan troglodytes microRNA...
11 1 gi|262205290|ref|NR_030188.1| Homo sapiens microRNA 51...
12 1 gi|301171354|ref|NR_035860.1| Pan troglodytes microRNA...
13 1 gi|262205281|ref|NR_030186.1| Homo sapiens microRNA 52...
14 2 gi|262205298|ref|NR_030190.1| Homo sapiens microRNA 52...
15 1 gi|301171394|ref|NR_035865.1| Pan troglodytes microRNA...
16 1 gi|262205429|ref|NR_030218.1| Homo sapiens microRNA 51...
17 1 gi|262205423|ref|NR_030217.1| Homo sapiens microRNA 52...
18 1 gi|301171401|ref|NR_035866.1| Pan troglodytes microRNA...
19 1 gi|270133247|ref|NR_032574.1| Macaca mulatta microRNA ...
20 1 gi|262205309|ref|NR_030193.1| Homo sapiens microRNA 52...
21 2 gi|270132717|ref|NR_032716.1| Macaca mulatta microRNA ...
22 2 gi|301171437|ref|NR_035870.1| Pan troglodytes microRNA...
23 2 gi|270133306|ref|NR_032587.1| Macaca mulatta microRNA ...
24 2 gi|301171428|ref|NR_035869.1| Pan troglodytes microRNA...
25 1 gi|301171211|ref|NR_035845.1| Pan troglodytes microRNA...
26 2 gi|301171153|ref|NR_035838.1| Pan troglodytes microRNA...
27 2 gi|301171146|ref|NR_035837.1| Pan troglodytes microRNA...
28 2 gi|270133254|ref|NR_032575.1| Macaca mulatta microRNA ...
29 2 gi|262205445|ref|NR_030221.1| Homo sapiens microRNA 51...
~~~
97 1 gi|356517317|ref|XM_003527287.1| PREDICTED: Glycine ma...
98 1 gi|297814701|ref|XM_002875188.1| Arabidopsis lyrata su...
99 1 gi|397513516|ref|XM_003827011.1| PREDICTED: Pan panisc...
通常,您一次會執行一個 BLAST 搜尋。然後,您需要做的就是提取 blast_records 中的第一個(也是唯一的)BLAST 記錄
>>> from Bio import Blast
>>> blast_records = Blast.parse("my_blast.xml")
>>> blast_record = next(blast_records)
或更優雅地
>>> from Bio import Blast
>>> blast_record = Blast.read(result_stream)
或等效地
>>> from Bio import Blast
>>> blast_record = Blast.read("my_blast.xml")
(在這裡,您不需要使用 with 區塊,因為 Blast.read 會讀取整個檔案並立即關閉它)。
我想你現在一定很想知道 BLAST 記錄中包含哪些內容。
BLAST 記錄、Record 和 Hit 類別
BLAST Records 類別
單一 BLAST 輸出檔案可能包含多個 BLAST 查詢的輸出結果。在 Biopython 中,BLAST 輸出檔案中的資訊會儲存在 Bio.Blast.Records 物件中。這是一個迭代器,會為每個查詢返回一個 Bio.Blast.Record 物件(請參閱子章節 BLAST Record 類別)。Bio.Blast.Records 物件具有下列屬性,描述 BLAST 執行:
source:建構Bio.Blast.Records物件的輸入資料來源(可以是檔案名稱或路徑,或是類似檔案的物件)。program:使用的特定 BLAST 程式(例如,'blastn')。version:BLAST 程式的版本(例如,'BLASTN 2.2.27+')。reference:BLAST 出版的文獻參考。db:執行查詢時所對應的 BLAST 資料庫(例如,'nr')。query:一個SeqRecord物件,可能包含以下部分或所有資訊:query.id:查詢的 SeqId;query.description:查詢的定義行;query.seq:查詢序列。
param:一個字典,包含 BLAST 執行時使用的參數。你可能會在此字典中找到以下鍵:'matrix':BLAST 執行中使用的計分矩陣(例如,'BLOSUM62')(字串);'expect':預期隨機匹配數量的閾值(浮點數);'include':在 psiblast 中,包含在多重比對模型中的 e 值閾值(浮點數);'sc-match':匹配核苷酸的分數(整數);'sc-mismatch':不匹配核苷酸的分數(整數);'gap-open':間隙開放成本(整數);'gap-extend':間隙延伸成本(整數);'filter':在 BLAST 執行中套用的過濾選項(字串);'pattern':PHI-BLAST 模式(字串);'entrez-query':限制對 Entrez 查詢的請求(字串)。
mbstat:一個字典,包含 Mega BLAST 搜尋統計資訊。有關此字典中項目的描述,請參閱下方Record.stat屬性的描述(在子章節 BLAST Record 類別 中)。只有舊版本的 Mega BLAST 會儲存此資訊。由於此資訊儲存在 BLAST 輸出檔案的末尾附近,因此只有在完整讀取檔案後(透過迭代記錄直到發出StopIteration)才能存取此屬性。
在我們的範例中,我們發現
>>> blast_records
<Bio.Blast.Records source='my_blast.xml' program='blastn' version='BLASTN 2.2.27+' db='refseq_rna'>
>>> blast_records.source
'my_blast.xml'
>>> blast_records.program
'blastn'
>>> blast_records.version
'BLASTN 2.2.27+'
>>> blast_records.reference
'Stephen F. Altschul, Thomas L. Madden, Alejandro A. Schäffer, Jinghui Zhang, Zheng Zhang, Webb Miller, and David J. Lipman (1997), "Gapped BLAST and PSI-BLAST: a new generation of protein database search programs", Nucleic Acids Res. 25:3389-3402.'
>>> blast_records.db
'refseq_rna'
>>> blast_records.param
{'expect': 10.0, 'sc-match': 2, 'sc-mismatch': -3, 'gap-open': 5, 'gap-extend': 2, 'filter': 'L;m;'}
>>> print(blast_records)
Program: BLASTN 2.2.27+
db: refseq_rna
Query: 42291 (length=61)
mystery_seq
Hits: ---- ----- ----------------------------------------------------------
# # HSP ID + description
---- ----- ----------------------------------------------------------
0 1 gi|262205317|ref|NR_030195.1| Homo sapiens microRNA 52...
1 1 gi|301171311|ref|NR_035856.1| Pan troglodytes microRNA...
2 1 gi|270133242|ref|NR_032573.1| Macaca mulatta microRNA ...
3 2 gi|301171322|ref|NR_035857.1| Pan troglodytes microRNA...
...
BLAST Record 類別
Bio.Blast.Record 物件會儲存 BLAST 為單一查詢提供的資訊。Bio.Blast.Record 類別繼承自 list,本質上是一個 Bio.Blast.Hit 物件的列表(請參閱章節 BLAST Hit 類別)。Bio.Blast.Record 物件具有以下兩個屬性:
query:一個SeqRecord物件,可能包含以下部分或所有資訊:query.id:查詢的 SeqId;query.description:查詢的定義行;query.seq:查詢序列。
stat:一個字典,包含 BLAST 比對的統計資料。你可能會在此字典中找到以下鍵:'db-num':BLAST 資料庫中的序列數量(整數);'db-len':BLAST 資料庫的長度(整數);'hsp-len':有效 HSP(高分片段對)長度(整數);'eff-space':有效搜尋空間(浮點數);'kappa':Karlin-Altschul 參數 K(浮點數);'lambda':Karlin-Altschul 參數 Lambda(浮點數);'entropy':Karlin-Altschul 參數 H(浮點數);
message:一些(錯誤?)資訊。
繼續我們的範例,
>>> blast_record
<Bio.Blast.Record query.id='42291'; 100 hits>
>>> blast_record.query
SeqRecord(seq=Seq(None, length=61), id='42291', name='<unknown name>', description='mystery_seq', dbxrefs=[])
>>> blast_record.stat
{'db-num': 3056429, 'db-len': 673143725, 'hsp-len': 0, 'eff-space': 0, 'kappa': 0.41, 'lambda': 0.625, 'entropy': 0.78}
>>> print(blast_record)
Query: 42291 (length=61)
mystery_seq
Hits: ---- ----- ----------------------------------------------------------
# # HSP ID + description
---- ----- ----------------------------------------------------------
0 1 gi|262205317|ref|NR_030195.1| Homo sapiens microRNA 52...
1 1 gi|301171311|ref|NR_035856.1| Pan troglodytes microRNA...
2 1 gi|270133242|ref|NR_032573.1| Macaca mulatta microRNA ...
3 2 gi|301171322|ref|NR_035857.1| Pan troglodytes microRNA...
...
由於 Bio.Blast.Record 類別繼承自 list,你可以將其作為列表使用。例如,你可以迭代記錄:
>>> for hit in blast_record:
... hit
...
<Bio.Blast.Hit target.id='gi|262205317|ref|NR_030195.1|' query.id='42291'; 1 HSP>
<Bio.Blast.Hit target.id='gi|301171311|ref|NR_035856.1|' query.id='42291'; 1 HSP>
<Bio.Blast.Hit target.id='gi|270133242|ref|NR_032573.1|' query.id='42291'; 1 HSP>
<Bio.Blast.Hit target.id='gi|301171322|ref|NR_035857.1|' query.id='42291'; 2 HSPs>
<Bio.Blast.Hit target.id='gi|301171267|ref|NR_035851.1|' query.id='42291'; 1 HSP>
...
若要檢查 blast_record 有多少個比對,你可以簡單地調用 Python 的 len 函數:
>>> len(blast_record)
100
與 Python 列表一樣,你可以使用索引從 Bio.Blast.Record 中擷取比對:
>>> blast_record[0] # retrieves the top hit
<Bio.Blast.Hit target.id='gi|262205317|ref|NR_030195.1|' query.id='42291'; 1 HSP>
>>> blast_record[-1] # retrieves the last hit
<Bio.Blast.Hit target.id='gi|397513516|ref|XM_003827011.1|' query.id='42291'; 1 HSP>
若要從 Bio.Blast.Record 中擷取多個比對,你可以使用切片表示法。這會返回一個新的 Bio.Blast.Record 物件,其中僅包含切片的比對:
>>> blast_slice = blast_record[:3] # slices the first three hits
>>> print(blast_slice)
Query: 42291 (length=61)
mystery_seq
Hits: ---- ----- ----------------------------------------------------------
# # HSP ID + description
---- ----- ----------------------------------------------------------
0 1 gi|262205317|ref|NR_030195.1| Homo sapiens microRNA 52...
1 1 gi|301171311|ref|NR_035856.1| Pan troglodytes microRNA...
2 1 gi|270133242|ref|NR_032573.1| Macaca mulatta microRNA ...
若要建立 Bio.Blast.Record 的副本,請取完整切片:
>>> blast_record_copy = blast_record[:]
>>> type(blast_record_copy)
<class 'Bio.Blast.Record'>
>>> blast_record_copy # list of all hits
<Bio.Blast.Record query.id='42291'; 100 hits>
如果你想要排序或篩選 BLAST 記錄(請參閱 排序和篩選 BLAST 輸出),但想要保留原始 BLAST 輸出的副本,則這特別有用。
你也可以將 blast_record 作為 Python 字典存取,並使用比對的 ID 作為鍵來擷取比對:
>>> blast_record["gi|262205317|ref|NR_030195.1|"]
<Bio.Blast.Hit target.id='gi|262205317|ref|NR_030195.1|' query.id='42291'; 1 HSP>
如果在 blast_record 中找不到 ID,則會引發 KeyError:
>>> blast_record["unicorn_gene"]
Traceback (most recent call last):
...
KeyError: 'unicorn_gene'
你可以像平常一樣使用 .keys() 取得完整的鍵列表:
>>> blast_record.keys()
['gi|262205317|ref|NR_030195.1|', 'gi|301171311|ref|NR_035856.1|', 'gi|270133242|ref|NR_032573.1|', ...]
如果你只想檢查特定比對是否存在於查詢結果中該怎麼辦?你可以使用 in 關鍵字執行簡單的 Python 成員資格測試:
>>> "gi|262205317|ref|NR_030195.1|" in blast_record
True
>>> "gi|262205317|ref|NR_030194.1|" in blast_record
False
有時候,知道比對是否存在還不夠;你還想知道比對的排名。在這裡,index 方法可以派上用場:
>>> blast_record.index("gi|301171437|ref|NR_035870.1|")
22
請記住,Python 使用以零為基底的索引,因此第一個比對的索引為 0。
BLAST Hit 類別
在 blast_record 列表中的每個 Bio.Blast.Hit 物件代表查詢與目標的比對結果。
>>> hit = blast_record[0]
>>> hit
<Bio.Blast.Hit target.id='gi|262205317|ref|NR_030195.1|' query.id='42291'; 1 HSP>
>>> hit.target
SeqRecord(seq=Seq(None, length=61), id='gi|262205317|ref|NR_030195.1|', name='NR_030195', description='Homo sapiens microRNA 520b (MIR520B), microRNA', dbxrefs=[])
我們可以透過列印來取得 hit 的摘要:
>>> print(blast_record[3])
Query: 42291
mystery_seq
Hit: gi|301171322|ref|NR_035857.1| (length=86)
Pan troglodytes microRNA mir-520c (MIR520C), microRNA
HSPs: ---- -------- --------- ------ --------------- ---------------------
# E-value Bit score Span Query range Hit range
---- -------- --------- ------ --------------- ---------------------
0 8.9e-20 100.47 60 [1:61] [13:73]
1 3.3e-06 55.39 60 [0:60] [73:13]
你可以看到我們在這裡涵蓋了要點:
比對始終針對一個查詢;查詢 ID 和描述會顯示在摘要的頂端。
比對包含查詢與一個目標序列的一個或多個比對。目標資訊會顯示在摘要的下一部分。如上所示,可以透過比對的
target屬性存取目標。最後,有一個表格,其中包含每個比對所包含的比對的快速資訊。在 BLAST 術語中,這些比對稱為「高分片段對」,或 HSP(請參閱章節 BLAST HSP 類別)。表格中的每一列都會摘要一個 HSP,包括 HSP 索引、e 值、位元分數、跨度(包括間隙的比對長度)、查詢座標和目標座標。
Bio.Blast.Hit 類別是 Bio.Align.Alignments(複數;請參閱章節 Alignments 類別)的子類別,因此本質上是 Bio.Align.Alignment(單數;請參閱章節 Alignment 物件)物件的列表。特別是當針對基因組比對核苷酸序列時,如果特定的查詢比對到染色體的多個區域,則 Bio.Blast.Hit 物件可能會包含多個 Bio.Align.Alignment。對於蛋白質比對,比對通常只包含一個比對,尤其是對於高度同源序列的比對。
>>> type(hit)
<class 'Bio.Blast.Hit'>
>>> from Bio.Align import Alignments
>>> isinstance(hit, Alignments)
True
>>> len(hit)
1
對於 XML2 格式的 BLAST 輸出,比對可能有多個具有相同序列但具有不同序列 ID 和描述的目標。這些目標可以作為 hit.targets 屬性存取。在大多數情況下,hit.targets 的長度為 1,並且僅包含 hit.target。
>>> from Bio import Blast
>>> blast_record = Blast.read("xml_2900_blastx_001_v2.xml")
>>> for hit in blast_record:
... print(len(hit.targets))
...
1
1
2
1
1
1
1
1
1
1
但是,正如你可以在上面的輸出中看到,第三個比對有多個目標。
>>> hit = blast_record[2]
>>> hit.targets[0].seq
Seq(None, length=246)
>>> hit.targets[1].seq
Seq(None, length=246)
>>> hit.targets[0].id
'gi|684409690|ref|XP_009175831.1|'
>>> hit.targets[1].id
'gi|663044098|gb|KER20427.1|'
>>> hit.targets[0].name
'XP_009175831'
>>> hit.targets[1].name
'KER20427'
>>> hit.targets[0].description
'hypothetical protein T265_11027 [Opisthorchis viverrini]'
>>> hit.targets[1].description
'hypothetical protein T265_11027 [Opisthorchis viverrini]'
由於兩個目標的序列內容彼此相同,因此它們的序列比對也相同。因此,此比對的比對僅參考 hit.targets[0](與 hit.target 相同),因為 hit.targets[1] 的比對也會相同。
BLAST HSP 類別
讓我們回到我們的主要範例,並查看第一個比對中第一個(也是唯一的)比對。此比對是 Bio.Blast.HSP 類別的實例,該類別是 Bio.Align 中的 Alignment 類別的子類別。
>>> from Bio import Blast
>>> blast_record = Blast.read("my_blast.xml")
>>> hit = blast_record[0]
>>> len(hit)
1
>>> alignment = hit[0]
>>> alignment
<Bio.Blast.HSP target.id='gi|262205317|ref|NR_030195.1|' query.id='42291'; 2 rows x 61 columns>
>>> type(alignment)
<class 'Bio.Blast.HSP'>
>>> from Bio.Align import Alignment
>>> isinstance(alignment, Alignment)
True
alignment 物件具有指向目標和查詢序列的屬性,以及一個描述序列比對的 coordinates 屬性。
>>> alignment.target
SeqRecord(seq=Seq('CCCTCTACAGGGAAGCGCTTTCTGTTGTCTGAAAGAAAAGAAAGTGCTTCCTTT...GGG'), id='gi|262205317|ref|NR_030195.1|', name='NR_030195', description='Homo sapiens microRNA 520b (MIR520B), microRNA', dbxrefs=[])
>>> alignment.query
SeqRecord(seq=Seq('CCCTCTACAGGGAAGCGCTTTCTGTTGTCTGAAAGAAAAGAAAGTGCTTCCTTT...GGG'), id='42291', name='<unknown name>', description='mystery_seq', dbxrefs=[])
>>> alignment.target
SeqRecord(seq=Seq('CCCTCTACAGGGAAGCGCTTTCTGTTGTCTGAAAGAAAAGAAAGTGCTTCCTTT...GGG'), id='gi|262205317|ref|NR_030195.1|', name='NR_030195', description='Homo sapiens microRNA 520b (MIR520B), microRNA', dbxrefs=[])
>>> alignment.query
SeqRecord(seq=Seq('CCCTCTACAGGGAAGCGCTTTCTGTTGTCTGAAAGAAAAGAAAGTGCTTCCTTT...GGG'), id='42291', name='<unknown name>', description='mystery_seq', dbxrefs=[])
>>> print(alignment.coordinates)
[[ 0 61]
[ 0 61]]
對於翻譯後的 BLAST 搜尋,目標或查詢的 features 屬性可能包含類型為 CDS 的 SeqFeature,該 CDS 會儲存氨基酸序列區域。此類特徵的 qualifiers 屬性是一個字典,其中包含單個鍵 'coded_by';對應的值會以基於 1 的座標的 GenBank 樣式字串指定編碼氨基酸序列的核苷酸序列區域。
每個 Alignment 物件都有以下額外的屬性
score: 高分配對 (High Scoring Pair, HSP) 的分數;annotations: 一個字典,可能包含以下鍵值'bit score': HSP 的分數(以位元為單位)(浮點數);'evalue': HSP 的 e-value (浮點數);'identity':HSP 中相同配對的數量 (整數);'positive': HSP 中正向配對的數量 (整數);'gaps': HSP 中缺口的數量 (整數);'midline': 格式化的中間線。
常用的 Alignment 方法 (請參閱Alignment 物件章節) 可以應用於 alignment。例如,我們可以印出比對結果
>>> print(alignment)
Query : 42291 Length: 61 Strand: Plus
mystery_seq
Target: gi|262205317|ref|NR_030195.1| Length: 61 Strand: Plus
Homo sapiens microRNA 520b (MIR520B), microRNA
Score:111 bits(122), Expect:5e-23,
Identities:61/61(100%), Positives:61/61(100%), Gaps:0.61(0%)
gi|262205 0 CCCTCTACAGGGAAGCGCTTTCTGTTGTCTGAAAGAAAAGAAAGTGCTTCCTTTTAGAGG
0 ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
42291 0 CCCTCTACAGGGAAGCGCTTTCTGTTGTCTGAAAGAAAAGAAAGTGCTTCCTTTTAGAGG
gi|262205 60 G 61
60 | 61
42291 60 G 61
讓我們印出 BLAST 記錄中所有高於特定閾值的比對結果的摘要資訊
>>> E_VALUE_THRESH = 0.04
>>> for alignments in blast_record:
... for alignment in alignments:
... if alignment.annotations["evalue"] < E_VALUE_THRESH:
... print("****Alignment****")
... print("sequence:", alignment.target.id, alignment.target.description)
... print("length:", len(alignment.target))
... print("score:", alignment.score)
... print("e value:", alignment.annotations["evalue"])
... print(alignment[:, :50])
...
****Alignment****
sequence: gi|262205317|ref|NR_030195.1| Homo sapiens microRNA 520b (MIR520B), microRNA
length: 61
score: 122.0
e value: 4.91307e-23
gi|262205 0 CCCTCTACAGGGAAGCGCTTTCTGTTGTCTGAAAGAAAAGAAAGTGCTTC 50
0 |||||||||||||||||||||||||||||||||||||||||||||||||| 50
42291 0 CCCTCTACAGGGAAGCGCTTTCTGTTGTCTGAAAGAAAAGAAAGTGCTTC 50
****Alignment****
sequence: gi|301171311|ref|NR_035856.1| Pan troglodytes microRNA mir-520b (MIR520B), microRNA
length: 60
score: 120.0
e value: 1.71483e-22
gi|301171 0 CCTCTACAGGGAAGCGCTTTCTGTTGTCTGAAAGAAAAGAAAGTGCTTCC 50
0 |||||||||||||||||||||||||||||||||||||||||||||||||| 50
42291 1 CCTCTACAGGGAAGCGCTTTCTGTTGTCTGAAAGAAAAGAAAGTGCTTCC 51
****Alignment****
sequence: gi|270133242|ref|NR_032573.1| Macaca mulatta microRNA mir-519a (MIR519A), microRNA
length: 85
score: 112.0
e value: 2.54503e-20
gi|270133 12 CCCTCTAGAGGGAAGCGCTTTCTGTGGTCTGAAAGAAAAGAAAGTGCTTC 62
0 |||||||.|||||||||||||||||.|||||||||||||||||||||||| 50
42291 0 CCCTCTACAGGGAAGCGCTTTCTGTTGTCTGAAAGAAAAGAAAGTGCTTC 50
...
排序和篩選 BLAST 輸出
如果 BLAST 輸出檔案中的比對結果順序不符合您的喜好,您可以使用 sort 方法重新排序 Bio.Blast.Record 物件中的比對結果。例如,這裡我們根據每個目標的序列長度對比對結果進行排序,並將 reverse 標誌設定為 True,以便按降序排序。
>>> for hit in blast_record[:5]:
... print(f"{hit.target.id} {len(hit.target)}")
...
gi|262205317|ref|NR_030195.1| 61
gi|301171311|ref|NR_035856.1| 60
gi|270133242|ref|NR_032573.1| 85
gi|301171322|ref|NR_035857.1| 86
gi|301171267|ref|NR_035851.1| 80
>>> sort_key = lambda hit: len(hit.target)
>>> blast_record.sort(key=sort_key, reverse=True)
>>> for hit in blast_recordt[:5]:
... print(f"{hit.target.id} {len(hit.target)}")
...
gi|397513516|ref|XM_003827011.1| 6002
gi|390332045|ref|XM_776818.2| 4082
gi|390332043|ref|XM_003723358.1| 4079
gi|356517317|ref|XM_003527287.1| 3251
gi|356543101|ref|XM_003539954.1| 2936
這將原地排序 blast_record。如果您想保留原始未排序的 BLAST 輸出副本,請在排序之前使用 original_blast_record = blast_record[:]。
若要根據 BLAST 比對結果的屬性進行篩選,您可以使用 Python 的內建 filter 函數,並搭配適當的回呼函數來評估每個比對結果。回呼函數必須接受單一 Hit 物件作為引數,並傳回 True 或 False。以下範例示範如何篩選出只有一個 HSP 的 Hit 物件
>>> filter_func = lambda hit: len(hit) > 1 # the callback function
>>> len(blast_record) # no. of hits before filtering
100
>>> blast_record[:] = filter(filter_func, blast_record)
>>> len(blast_record) # no. of hits after filtering
37
>>> for hit in blast_record[:5]: # quick check for the hit lengths
... print(f"{hit.target.id} {len(hit)}")
...
gi|301171322|ref|NR_035857.1| 2
gi|262205330|ref|NR_030198.1| 2
gi|301171447|ref|NR_035871.1| 2
gi|262205298|ref|NR_030190.1| 2
gi|270132717|ref|NR_032716.1| 2
同樣地,您可以篩選每個比對結果中的 HSP,例如根據其 e-value 進行篩選
>>> filter_func = lambda hsp: hsp.annotations["evalue"] < 1.0e-12
>>> for hit in blast_record:
... hit[:] = filter(filter_func, hit)
...
您可能需要接著移除所有沒有剩餘 HSP 的比對結果
>>> filter_func = lambda hit: len(hit) > 0
>>> blast_record[:] = filter(filter_func, blast_record)
>>> len(blast_record)
16
使用 Python 的內建 map 函數來修改 BLAST 記錄中的比對結果或 HSP。map 函數接受一個回呼函數,該函數會傳回修改後的比對結果物件。例如,我們可以使用 map 來重新命名比對結果的 ID
>>> for hit in blast_record[:5]:
... print(hit.target.id)
...
gi|301171322|ref|NR_035857.1|
gi|262205330|ref|NR_030198.1|
gi|301171447|ref|NR_035871.1|
gi|262205298|ref|NR_030190.1|
gi|270132717|ref|NR_032716.1|
>>> import copy
>>> original_blast_record = copy.deepcopy(blast_record)
>>> def map_func(hit):
... # renames "gi|301171322|ref|NR_035857.1|" to "NR_035857.1"
... hit.target.id = hit.target.id.split("|")[3]
... return hit
...
>>> blast_record[:] = map(map_func, blast_record)
>>> for hit in blast_record[:5]:
... print(hit.target.id)
...
NR_035857.1
NR_030198.1
NR_035871.1
NR_030190.1
NR_032716.1
>>> for hit in original_blast_record[:5]:
... print(hit.target.id)
...
gi|301171322|ref|NR_035857.1|
gi|262205330|ref|NR_030198.1|
gi|301171447|ref|NR_035871.1|
gi|262205298|ref|NR_030190.1|
gi|270132717|ref|NR_032716.1|
請注意,在這個範例中,map_func 會就地修改比對結果。與排序和篩選 (見上文) 不同,使用 original_blast_record = blast_record[:] 不足以保留未修改的 BLAST 記錄副本,因為它會建立 BLAST 記錄的淺層副本,其中包含指向相同 Hit 物件的指標。相反地,我們使用 copy.deepcopy 來建立 BLAST 記錄的副本,其中每個 Hit 物件都會被複製。
寫入 BLAST 記錄
使用 Bio.Blast 中的 write 函數將 BLAST 記錄儲存為 XML 檔案。預設情況下,使用 (基於 DTD 的) XML 格式;您也可以透過將 fmt="XML2" 引數傳遞給 write 函數,以 (基於綱要的) XML2 格式儲存 BLAST 記錄。
>>> from Bio import Blast
>>> stream = Blast.qblast("blastn", "nt", "8332116")
>>> records = Blast.parse(stream)
>>> Blast.write(records, "my_qblast_output.xml")
or
>>> Blast.write(records, "my_qblast_output.xml", fmt="XML2")
在這個範例中,我們可以將 Blast.qblast 傳回的資料直接儲存到 XML 檔案中 (請參閱儲存 BLAST 結果章節)。然而,透過將 qblast 傳回的資料解析成記錄,我們可以在儲存之前對 BLAST 記錄進行排序或篩選。例如,我們可能只對正向分數至少為 400 的 BLAST HSP 感興趣
>>> filter_func = lambda hsp: hsp.annotations["positive"] >= 400
>>> for hit in records[0]:
... hit[:] = filter(filter_func, hit)
...
>>> Blast.write(records, "my_qblast_output_selected.xml")
除了檔案名稱之外,Blast.write 的第二個引數也可以是檔案串流。在這種情況下,串流必須以二進制格式開啟以進行寫入
>>> with open("my_qblast_output.xml", "wb") as stream:
... Blast.write(records, stream)
...
處理 PSI-BLAST
您可以直接從命令列或使用 Python 的 subprocess 模組執行 PSI-BLAST 的獨立版本 (psiblast)。
在撰寫本文時,NCBI 似乎不支援透過網路執行 PSI-BLAST 搜尋的工具。
請注意,Bio.Blast 解析器可以讀取目前版本的 PSI-BLAST 的 XML 輸出,但 XML 檔案中沒有每個迭代中的哪些序列是新的或重複使用的資訊。
處理 RPS-BLAST
您可以直接從命令列或使用 Python 的 subprocess 模組執行 RPS-BLAST 的獨立版本 (rpsblast)。
在撰寫本文時,NCBI 似乎不支援透過網路執行 RPS-BLAST 搜尋的工具。
您可以使用 Bio.Blast 解析器來讀取目前版本的 RPS-BLAST 的 XML 輸出。
BLAST (舊版)
嘿,大家都很喜歡 BLAST 對吧?我的意思是,天啊,要比較你的序列和已知世界中的其他序列,怎麼可能更簡單呢?但是,當然,本節不是在講 BLAST 有多酷,因為我們已經知道了。它是關於 BLAST 的問題 – 處理大型執行產生的大量數據,以及自動化 BLAST 執行通常會非常困難。
幸運的是,Biopython 的人們非常清楚這一點,所以他們開發了許多工具來處理 BLAST,使事情變得更加容易。本節詳細介紹如何使用這些工具並用它們做有用的事情。
處理 BLAST 可以分為兩個步驟,這兩個步驟都可以在 Biopython 中完成。首先,為您的查詢序列執行 BLAST,並取得一些輸出。其次,在 Python 中解析 BLAST 輸出,以便進行進一步的分析。
您第一次接觸執行 BLAST 可能透過 NCBI 網路服務。事實上,有很多種方法可以執行 BLAST,可以透過幾種方式進行分類。最重要的區別是在本地 (在您自己的機器上) 執行 BLAST 和遠端 (在另一台機器上,通常是 NCBI 伺服器) 執行 BLAST。我們將在本章開始時,從 Python 腳本中調用 NCBI 線上 BLAST 服務。
注意:以下章節BLAST 和其他序列搜尋工具描述了 Bio.SearchIO。我們打算最終用這個模組取代舊的 Bio.Blast 模組,因為它提供了一個更通用的框架來處理其他相關的序列搜尋工具。但是,現在您可以使用它或舊的 Bio.Blast 模組來處理 NCBI BLAST。
透過網際網路執行 BLAST
我們使用 Bio.Blast.NCBIWWW 模組中的 qblast() 函數來調用線上版本的 BLAST。這個函數有三個非選用的引數
第一個引數是要用於搜尋的 BLAST 程式,以小寫字串表示。這些程式的選項和說明可在 https://blast.ncbi.nlm.nih.gov/Blast.cgi 取得。目前
qblast僅適用於 blastn、blastp、blastx、tblast 和 tblastx。第二個引數指定要搜尋的資料庫。同樣地,此選項可在 NCBI BLAST 指南 https://blast.ncbi.nlm.nih.gov/doc/blast-help/ 中找到。
第三個參數是包含您的查詢序列的字串。這可以是序列本身、fasta 格式的序列,或是像 GI 編號這樣的識別碼。
NCBI 指南,來自 https://blast.ncbi.nlm.nih.gov/doc/blast-help/developerinfo.html#developerinfo 指出
不要以高於每 10 秒一次的頻率聯絡伺服器。
不要以高於每分鐘一次的頻率輪詢任何單一 RID。
使用 URL 參數 email 和 tool,以便 NCBI 在發生問題時可以聯絡您。
如果提交的搜尋超過 50 次,請在週末或平日東部時間晚上 9 點到凌晨 5 點之間執行腳本。
為了滿足第三點,可以設定 NCBIWWW.email 變數。
>>> from Bio.Blast import NCBIWWW
>>> NCBIWWW.email = "A.N.Other@example.com"
qblast 函式還接受許多其他選用參數,這些參數基本上類似於您可以在 BLAST 網頁上設定的不同參數。我們在這裡只會強調其中幾個
url_base參數會設定透過網際網路執行 BLAST 的基本 URL。預設情況下,它會連線到 NCBI,但是可以使用此選項來連線到在雲端中執行的 NCBI BLAST 實例。請參考qblast函式的說明文件,以取得更多詳細資訊。qblast函數可以傳回各種格式的 BLAST 結果,您可以使用選用的format_type關鍵字選擇:"HTML"、"Text"、"ASN.1"或"XML"。預設值為"XML",因為這是解析器預期的格式,如下面的解析 BLAST 輸出章節中所述。expect參數會設定期望值或 e 值閾值。
如需有關選用 BLAST 參數的更多資訊,我們建議您參考 NCBI 自己的說明文件,或內建於 Biopython 中的說明文件
>>> from Bio.Blast import NCBIWWW
>>> help(NCBIWWW.qblast)
請注意,NCBI BLAST 網站上的預設設定與 QBLAST 上的預設設定不太相同。如果您的結果不同,您需要檢查參數(例如,期望值閾值和間隙值)。
例如,如果您有一個想要使用 BLASTN 針對核苷酸資料庫 (nt) 搜尋的核苷酸序列,並且您知道您的查詢序列的 GI 編號,您可以使用
>>> from Bio.Blast import NCBIWWW
>>> result_handle = NCBIWWW.qblast("blastn", "nt", "8332116")
或者,如果我們的查詢序列已在 FASTA 格式的檔案中,我們只需要開啟檔案並將此記錄讀取為字串,並將其用作查詢參數
>>> from Bio.Blast import NCBIWWW
>>> fasta_string = open("m_cold.fasta").read()
>>> result_handle = NCBIWWW.qblast("blastn", "nt", fasta_string)
我們也可以將 FASTA 檔案讀取為 SeqRecord,然後僅提供序列本身
>>> from Bio.Blast import NCBIWWW
>>> from Bio import SeqIO
>>> record = SeqIO.read("m_cold.fasta", format="fasta")
>>> result_handle = NCBIWWW.qblast("blastn", "nt", record.seq)
僅提供序列表示 BLAST 將自動為您的序列指派一個識別碼。您可能更喜歡使用 SeqRecord 物件的 format 方法來製作 FASTA 字串 (其中將包含現有的識別碼)
>>> from Bio.Blast import NCBIWWW
>>> from Bio import SeqIO
>>> record = SeqIO.read("m_cold.fasta", format="fasta")
>>> result_handle = NCBIWWW.qblast("blastn", "nt", record.format("fasta"))
如果您將序列儲存在可以使用 Bio.SeqIO 擷取的非 FASTA 檔案格式中,則此方法更有意義(請參閱第 序列輸入/輸出章)。
無論您給 qblast() 函數什麼引數,您都應該以處理物件的形式取得結果 (預設為 XML 格式)。下一步是將 XML 輸出解析為代表搜尋結果的 Python 物件 (第解析 BLAST 輸出章節),但您可能想先儲存輸出檔案的本機副本。當我除錯從 BLAST 結果中擷取資訊的程式碼時,我發現這特別有用 (因為重新執行線上搜尋很慢且會浪費 NCBI 電腦的時間)。
我們需要小心一點,因為我們只能使用 result_handle.read() 讀取 BLAST 輸出一次 – 再次呼叫 result_handle.read() 會傳回空字串。
>>> with open("my_blast.xml", "w") as out_handle:
... out_handle.write(result_handle.read())
...
>>> result_handle.close()
執行此操作後,結果將位於 my_blast.xml 檔案中,並且原始處理已擷取了其所有資料 (因此我們關閉了它)。但是,BLAST 解析器的 parse 函數 (在解析 BLAST 輸出中描述) 採用類檔案處理物件,因此我們只需開啟儲存的檔案以進行輸入即可
>>> result_handle = open("my_blast.xml")
現在我們已經將 BLAST 結果再次放回處理中,我們已經準備好對它們進行處理,因此這將我們直接帶到解析章節 (請參閱下面的解析 BLAST 輸出章節)。您可能想現在跳到該章節……。
在本機執行 BLAST
簡介
在本機執行 BLAST(而不是透過網際網路,請參閱透過網際網路執行 BLAST一節)至少有兩個主要優點
在本機執行 BLAST 可能比透過網際網路執行 BLAST 更快;
在本機執行 BLAST 可讓您建立自己的資料庫來搜尋序列。
處理專有或未發表的序列數據可能是本地執行 BLAST 的另一個原因。您可能不被允許重新分發這些序列,因此將它們作為 BLAST 查詢提交給 NCBI 將不是一個可行的選項。
不幸的是,也有一些主要的缺點——安裝所有組件並正確設置需要一些努力
本地 BLAST 需要安裝命令列工具。
本地 BLAST 需要設置(且可能需要保持更新) (大型) BLAST 數據庫。
更令人困惑的是,有多個不同的 BLAST 套件可用,還有其他工具可以產生模仿 BLAST 輸出檔案,例如 BLAT。
獨立 NCBI BLAST+
「新的」NCBI BLAST+ 套件於 2009 年發布。這取代了舊的 NCBI「舊版」BLAST 套件 (見下文)。
本節將簡要展示如何從 Python 中使用這些工具。如果您已經閱讀或嘗試過第 比對工具 節中的比對工具範例,這一切應該看起來相當簡單。首先,我們建構一個命令列字串(就像您在手動執行獨立 BLAST 時在命令列提示符號中輸入的一樣)。然後我們可以從 Python 中執行這個命令。
例如,採用基因核苷酸序列的 FASTA 檔案,您可能想要針對非冗餘 (NR) 蛋白質數據庫執行 BLASTX(翻譯)搜尋。假設您(或您的系統管理員)已下載並安裝 NR 數據庫,您可能會執行
$ blastx -query opuntia.fasta -db nr -out opuntia.xml -evalue 0.001 -outfmt 5
這應該會針對 NR 數據庫執行 BLASTX,使用預期截止值 \(0.001\) 並產生 XML 輸出到指定的檔案(然後我們可以解析它)。在我的電腦上,這大約需要六分鐘——這是一個將輸出儲存到檔案的好理由,以便您可以根據需要重複任何分析。
在 Python 中,我們可以使用 subprocess 模組來建立命令列字串並執行它
>>> import subprocess
>>> cmd = "blastx -query opuntia.fasta -db nr -out opuntia.xml"
>>> cmd += " -evalue 0.001 -outfmt 5"
>>> subprocess.run(cmd, shell=True)
在這個範例中,不應該有來自 BLASTX 到終端機的任何輸出。您可能想要檢查輸出檔案 opuntia.xml 是否已建立。
您可能還記得本教學先前範例中,opuntia.fasta 包含七個序列,因此 BLAST XML 輸出應該包含多個結果。因此,請使用 Bio.Blast.NCBIXML.parse() 進行解析,如下方 解析 BLAST 輸出 章節所述。
其他版本的 BLAST
NCBI BLAST+ (以 C++ 編寫) 最初於 2009 年發布,用以取代原先的 NCBI 「舊版」 BLAST (以 C 編寫),該版本已不再更新。其中有許多變更 – 舊版本有一個單核心命令列工具 blastall,涵蓋多種不同的 BLAST 搜尋類型 (現在在 BLAST+ 中為獨立命令),並且所有命令列選項都已重新命名。Biopython 用於 NCBI「舊版」 BLAST 工具的包裝器已棄用,並將在未來版本中移除。為了避免混淆,本教學中我們不介紹如何從 Biopython 呼叫這些舊工具。
您可能也會遇到 華盛頓大學 BLAST (WU-BLAST),及其後繼者 Advanced Biocomputing BLAST (AB-BLAST,於 2009 年發布,非免費/開放原始碼)。這些套件包含命令列工具 wu-blastall 和 ab-blastall,它們模擬了 NCBI「舊版」 BLAST 套件中的 blastall。Biopython 目前不提供用於呼叫這些工具的包裝器,但應該能夠解析來自它們的任何 NCBI 相容輸出。
解析 BLAST 輸出
如上所述,BLAST 可以產生各種格式的輸出,例如 XML、HTML 和純文字。最初,Biopython 具有 BLAST 純文字和 HTML 輸出的解析器,因為這些是當時唯一提供的輸出格式。不幸的是,這些格式的 BLAST 輸出不斷變化,每次都破壞了 Biopython 解析器。我們的 HTML BLAST 解析器已被移除,而棄用的純文字 BLAST 解析器現在僅透過 Bio.SearchIO 提供。請自行承擔使用風險,它可能會也可能不會運作,具體取決於您使用的 BLAST 版本。
由於跟上 BLAST 的變化已變得遙不可及,尤其是在使用者執行不同 BLAST 版本的情況下,我們現在建議解析 XML 格式的輸出,該格式可以由最新版本的 BLAST 產生。XML 輸出不僅比純文字和 HTML 輸出更穩定,而且更容易自動解析,使 Biopython 更穩定。
您可以使用各種方式取得 XML 格式的 BLAST 輸出。對於剖析器來說,輸出是如何產生的並不重要,只要它是 XML 格式即可。
您可以按照第 透過網際網路執行 BLAST 節中的說明,使用 Biopython 透過網際網路執行 BLAST。
您可以按照第 在本機執行 BLAST 節中的說明,使用 Biopython 在本機執行 BLAST。
您可以自己在 NCBI 網站上透過網頁瀏覽器執行 BLAST 搜尋,然後儲存結果。您需要在接收結果時選擇 XML 作為格式,並將您獲得的最終 BLAST 頁面(您知道,包含所有有趣結果的那個!)儲存到檔案中。
您也可以在本機執行 BLAST 而不使用 Biopython,並將輸出儲存到檔案中。同樣,您需要在接收結果時選擇 XML 作為格式。
重點是,您不必使用 Biopython 腳本來取得資料才能夠解析它。以其中一種方式進行操作後,您需要取得結果的控制碼。在 Python 中,控制碼只是描述任何資訊來源的輸入的一種通用方式,以便可以使用 read() 和 readline() 函式來擷取資訊(請參閱 控制碼是什麼? 章節)。
如果您依照上方透過腳本與 BLAST 互動的程式碼,那麼您已經擁有 result_handle,這是 BLAST 結果的控制碼。例如,使用 GI 號碼進行線上搜尋
>>> from Bio.Blast import NCBIWWW
>>> result_handle = NCBIWWW.qblast("blastn", "nt", "8332116")
如果您以其他方式執行 BLAST,並在檔案 my_blast.xml 中有 BLAST 輸出 (XML 格式),您只需開啟檔案進行讀取
>>> result_handle = open("my_blast.xml")
現在我們有了控制碼,就可以準備解析輸出了。解析輸出的程式碼非常短。如果您預期單一 BLAST 結果 (也就是說,您使用了單一查詢)
>>> from Bio.Blast import NCBIXML
>>> blast_record = NCBIXML.read(result_handle)
或者,如果您有很多結果(即,多個查詢序列)
>>> from Bio.Blast import NCBIXML
>>> blast_records = NCBIXML.parse(result_handle)
就像 Bio.SeqIO 和 Bio.Align (請參閱 序列輸入/輸出 和 序列比對 章節) 一樣,我們有一對輸入函式 read 和 parse,其中 read 用於您只有一個物件的情況,而 parse 是一個迭代器,用於您可能有很多物件的情況 – 但我們不是取得 SeqRecord 或 MultipleSeqAlignment 物件,而是取得 BLAST 記錄物件。
為了能夠處理 BLAST 檔案可能很大,包含數千個結果的情況,NCBIXML.parse() 會傳回一個迭代器。簡單來說,迭代器允許您逐步執行 BLAST 輸出,針對每個 BLAST 搜尋結果逐一擷取 BLAST 記錄
>>> from Bio.Blast import NCBIXML
>>> blast_records = NCBIXML.parse(result_handle)
>>> blast_record = next(blast_records)
# ... do something with blast_record
>>> blast_record = next(blast_records)
# ... do something with blast_record
>>> blast_record = next(blast_records)
# ... do something with blast_record
>>> blast_record = next(blast_records)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
# No further records
或者,您可以使用 for 迴圈
>>> for blast_record in blast_records:
... pass # Do something with blast_record
...
但請注意,您只能逐步執行 BLAST 記錄一次。通常,您會從每個 BLAST 記錄中儲存您感興趣的資訊。如果您想儲存所有傳回的 BLAST 記錄,您可以將迭代器轉換為清單
>>> blast_records = list(blast_records)
現在您可以像平常一樣使用索引存取清單中的每個 BLAST 記錄。但是,如果您的 BLAST 檔案很大,您可能會因為嘗試將它們全部儲存到清單中而遇到記憶體問題。
通常,您一次會執行一個 BLAST 搜尋。然後,您需要做的就是提取 blast_records 中的第一個(也是唯一的)BLAST 記錄
>>> from Bio.Blast import NCBIXML
>>> blast_records = NCBIXML.parse(result_handle)
>>> blast_record = next(blast_records)
或更優雅地
>>> from Bio.Blast import NCBIXML
>>> blast_record = NCBIXML.read(result_handle)
我想你現在一定很想知道 BLAST 記錄中包含哪些內容。
BLAST 記錄類別
BLAST 記錄包含您可能想從 BLAST 輸出中擷取的所有內容。現在,我們只會展示如何從 BLAST 報告中取得一些資訊的範例,但如果您想要這裡未描述的特定內容,請詳細查看記錄類別上的資訊,並檢視程式碼或自動產生的文件 – 文件字串中有很多關於每條資訊中儲存內容的有用資訊。
為了繼續我們的範例,讓我們只印出 BLAST 報告中所有大於特定臨界值的命中摘要資訊。以下程式碼會執行此操作
>>> E_VALUE_THRESH = 0.04
>>> for alignment in blast_record.alignments:
... for hsp in alignment.hsps:
... if hsp.expect < E_VALUE_THRESH:
... print("****Alignment****")
... print("sequence:", alignment.title)
... print("length:", alignment.length)
... print("e value:", hsp.expect)
... print(hsp.query[0:75] + "...")
... print(hsp.match[0:75] + "...")
... print(hsp.sbjct[0:75] + "...")
...
這會印出如下所示的摘要報告
****Alignment****
sequence: >gb|AF283004.1|AF283004 Arabidopsis thaliana cold acclimation protein WCOR413-like protein
alpha form mRNA, complete cds
length: 783
e value: 0.034
tacttgttgatattggatcgaacaaactggagaaccaacatgctcacgtcacttttagtcccttacatattcctc...
||||||||| | ||||||||||| || |||| || || |||||||| |||||| | | |||||||| ||| ||...
tacttgttggtgttggatcgaaccaattggaagacgaatatgctcacatcacttctcattccttacatcttcttc...
基本上,一旦您解析完 BLAST 報告後,您可以使用其中的資訊執行任何您想執行的操作。當然,這取決於您想要將其用於什麼用途,但希望這能幫助您開始執行您需要執行的操作!
從 BLAST 報告中擷取資訊時,一個重要的考量是資訊儲存在其中的物件類型。在 Biopython 中,解析器會傳回 Record 物件,視您解析的內容而定,可能是 Blast 或 PSIBlast。這些物件定義於 Bio.Blast.Record 中,而且相當完整。
表示 BLAST 報告的 Blast 記錄類別的類別圖。 和 PSIBlast 記錄類別的類別圖。 是我嘗試建立的 Blast 和 PSIBlast 記錄類別的 UML 類別圖。PSIBlast 記錄物件類似,但支援 PSIBlast 迭代步驟中使用的回合。
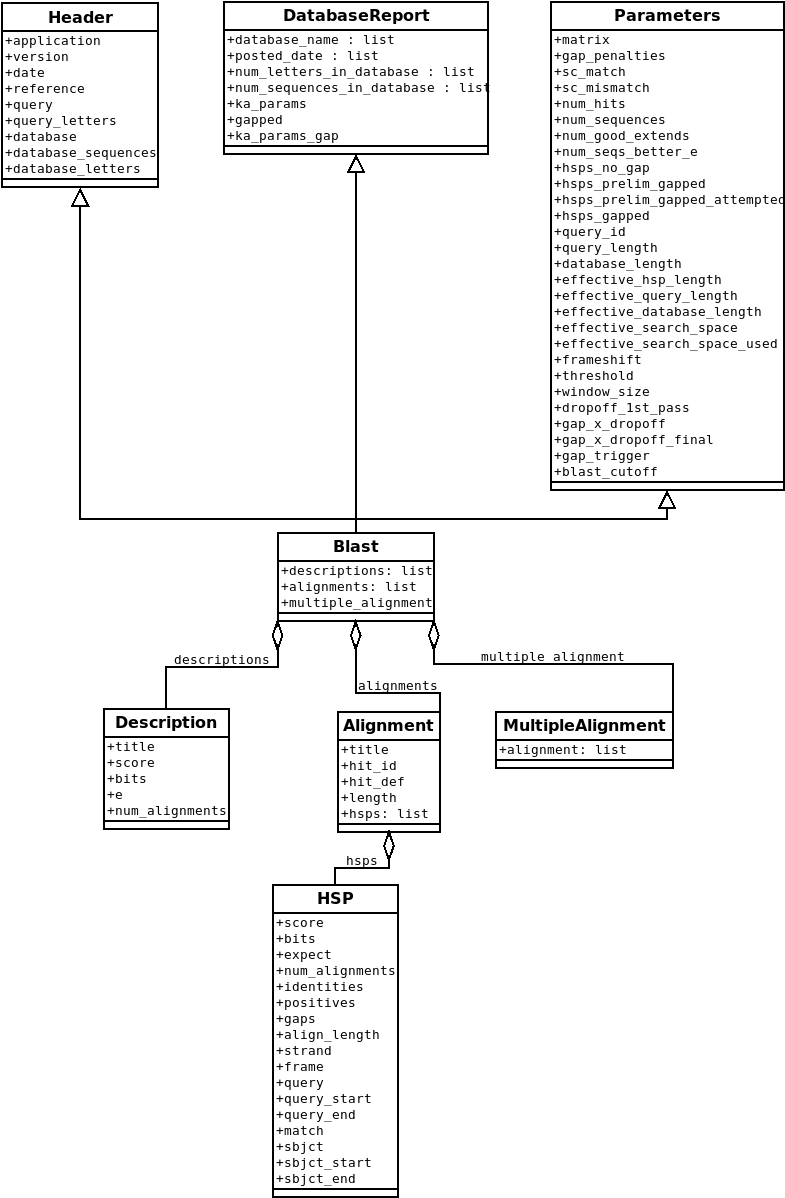
圖 1 表示 BLAST 報告的 Blast 記錄類別的類別圖。
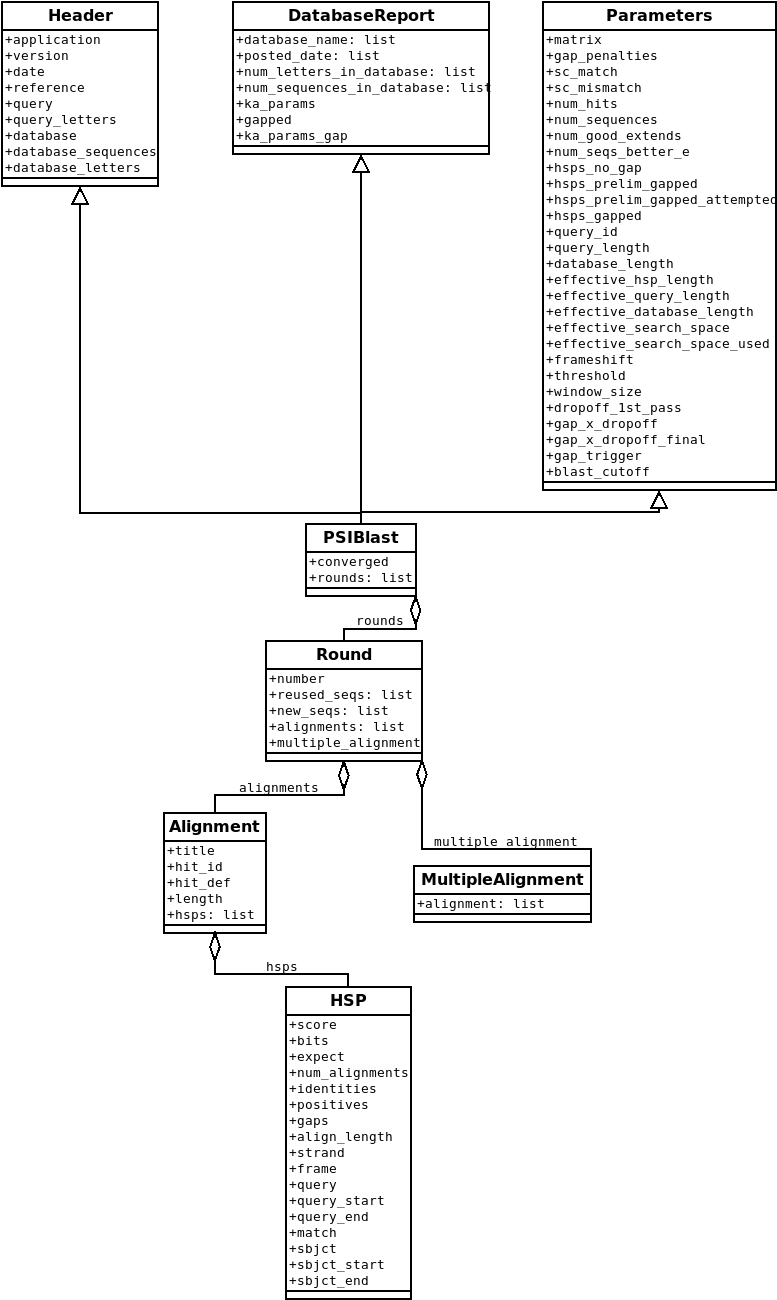
圖 2 PSIBlast 記錄類別的類別圖。
如果您擅長 UML,並且發現可以進行的錯誤/改進,請告知我。
處理 PSI-BLAST
您可以直接從命令列或使用 Python 的 subprocess 模組執行獨立版本的 PSI-BLAST (舊版 NCBI 命令列工具 blastpgp 或其替代工具 psiblast)。
在撰寫本文時,NCBI 似乎不支援透過網路執行 PSI-BLAST 搜尋的工具。
請注意,Bio.Blast.NCBIXML 解析器可以讀取目前版本 PSI-BLAST 的 XML 輸出,但 XML 檔案中不存在諸如每次迭代中哪些序列是新的或重複使用的資訊。
處理 RPS-BLAST
您可以直接從命令列或使用 Python 的 subprocess 模組執行獨立版本的 RPS-BLAST (舊版 NCBI 命令列工具 rpsblast 或其具有相同名稱的替代工具)。
在撰寫本文時,NCBI 似乎不支援透過網路執行 RPS-BLAST 搜尋的工具。
您可以使用 Bio.Blast.NCBIXML 解析器讀取目前版本 RPS-BLAST 的 XML 輸出。